MetaAI的硬件集群及其相关技术记录
LlaMA 3
2024年4月18日,Meta正式发布了最新一代的开源大型语言模型:LlaMA3。包括了预训练和指令微调的两个版本的模型,分别都提供了 8B 和 70B 参数的版本。其中8B 版本适合在消费级 GPU 上进行更为高效的部署和开发,而70B 版本则专为大规模 AI 应用设计。
该模型在 Meta 最近公布的两个定制的24K GPU集群上完成训练,所用数据集超过15万亿个token,其规模是Llama 2训练数据集的七倍之多,其中代码数据量更是Llama 2的四倍。这一过程造就了目前最为强大的Llama模型版本,能够支持长达8K的上下文长度,相较于Llama 2,处理能力也实现了两倍的扩容。
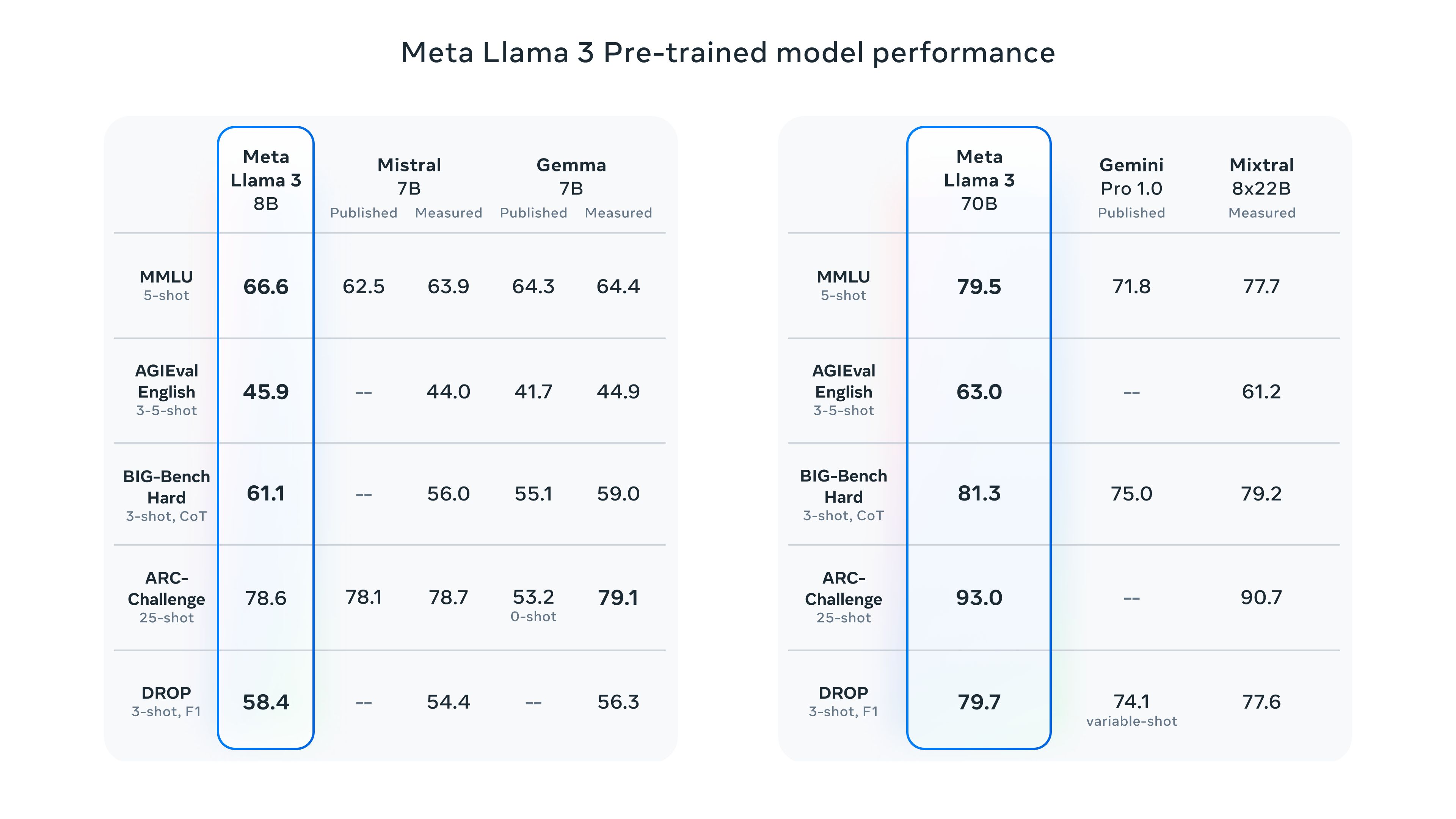
如下图所示,Llama3 作为预训练模型在性能方面,相比同规模的其他模型而言也在多个任务中拿到了 SOTA。
此外,Meta 还指出目前仍在训练的 Llama 3 的最大参数超过 400B 。蕴含的新功能包括多模态、多语言对话能力、更长的上下文以及更强的整体理解能力等,将在接下来的几个月中陆续发布。
待 Llama 3 400B+ 训练完成之际,Meta 还将正式发表一份详尽的研究论文。
官方网站👉Meta Llama 3
模型介绍📃Introducing Meta Llama 3: The most capable openly available LLM to date;开源大模型Llama 3王者归来 - 机器之心
相关介绍 🔔陈巍:LLaMA3大模型技术全网最全解析——模型架构与训练方法- 知乎
MetaAI Infrastructure
在前文讨论中,我们见证了Llama 3模型所展现出的卓越性能,自然而然地引出了一个核心问题:究竟是怎样的硬件基础设施才能支撑起如此庞大且智能的模型训练。针对这一疑问,Meta 于2024年3月12日发布的《Building Meta’s GenAI Infrastructure》报告,为我们详尽揭示了支撑Llama 3训练背后的主要计算集群架构。其主要框架如下图所示:

具体来说,在网络配置层面,该集群系统提供了RoCEv2(Remote Direct Memory Access over Converged Ethernet version 2)与 InfiniBand 两种先进的网络技术方案。其中 Llama3 模型的训练主要是依托于高性能的RoCEv2网络架构进行。而在存储方案上,集群使用了结合Tectonic分布式文件系统及Hammerspace管理平台的NFS(Network File System)/FUSE(Filesystem in Userspace)集成系统,以实现数据的高效存储与访问。
此外,集群沿用了标准的PyTorch深度学习框架,内部所做的所有更改都已合并到上游,确保了代码的可移植性和后续升级的便捷性。同时,通过与NCCL(NVIDIA Collective Communications Library)的紧密集成及其定制化补丁的应用,集群最大限度地优化了网络带宽的使用效率。另外,为保障系统的健壮性与运行效率,集群还集成了多种调试与监控工具,如NCCL desync debug、内存行重映射检测等,以确保集群的稳定运行和高效性能。
- Building Meta’s GenAI Infrastructure - Engineering at Meta (fb.com)
- Inside The Massive GPU Buildout At Meta Platforms (nextplatform.com)
- 【译】 Meta/Facebook 超大规模 AI/GPU 基础设施设计(2024) (arthurchiao.art)
- Meta用35万个H100,打造超级军火库
- Meta自曝其雄心勃勃的GenAI基础设施:计划2024年底,算力将达 60万个 H100 GPU
- 【第一代基础设施】Introducing the AI Research SuperCluster — Meta’s cutting-edge AI supercomputer for AI research
随后,本文将系统化地阐述构成该基础设施核心技术的相关细节,主要分为计算平台、网络架构、存储策略及性能优化四大板块进行探讨。
Grand Teton 平台
两个集群中,每个集群都装有 24,576 个 NVIDIA Tensor Core H100 GPU,使得两个集群版本都能够支持比集群中可支持的模型更大、更复杂的模型。其中采用“Grand Teton”计算平台装载。Grand Teton是Meta 在 OCP Summit 2022 中公布的,作为Zion-EX平台后继的下一代AI规模开放GPU硬件平台。其实物图如下:
在一台 Grand Teton 中可装 8 个 NVIDIA H100 GPU,并且相较于依赖外部线缆来连接三个独立组件组成的前任平台,Grand Teton直接将CPU主节点、交换机同步系统及GPU系统整合为单一机箱,内置完全集成的电源、控制、计算及结构接口,在整体性能、信号完整性和热性能上实现了优化。
相比之下,主机到GPU的带宽提升了4倍,计算和数据的网络带宽增加了2倍,而且包络功率也扩大了2倍。
RDMA 网络架构
Meta 考虑到优化人工智能研究员端到端的体验,同时确保数据中心高效运行以受理每天数数百万亿个 AI 任务执行需求,定制设计了自己的大部分硬件、软件和网络结构。
具体来说,针对两个集群分别设计了两个均能实现 400 Gbps 传输速率的网络方案。一是基于 Arista 7800 的 RoCE 网络结构,其中配备了 Wedge400 和 Minipack2 两种 Meta 自研并在此前开放在 Open Compute Project(OCP)的机架式交换机。二是直接使用 NVIDIA Quantum2 InfiniBand fabric。其中 Llama3 模型的训练主要是依托于高性能的RoCE网络架构进行。
上述两种网络技术均属于远程直接内存访问(RDMA)范畴,旨在降低数据传输延迟并提高效率,以下将对它们进行详细的解析。
RDMA
远程直接内存访问(Remote Direct Memory Access,RDMA)是一种能够在无需经过远程主机操作系统介入的情况下,直接访问目标主机内存数据的通信机制技术。
该机制有效规避了操作系统层面对数据传输的干预,从而极大地减少了CPU资源占用,提升了系统整体吞吐量,并显著降低了网络通信延迟,对于大规模并行计算集群环境下的数据密集型应用尤为适宜。
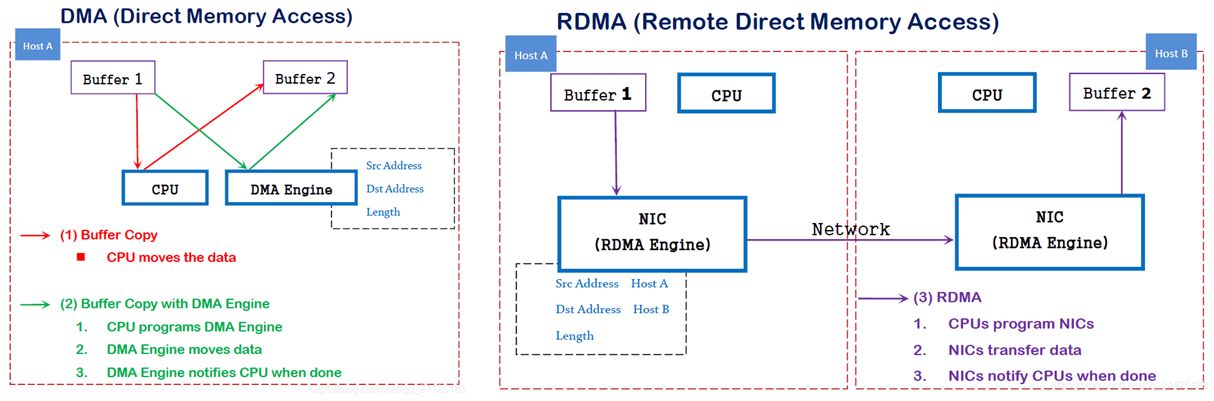
其概念源于计算机组成原理中的 DMA (Direct Memory Access)技术。DMA旨在通过允许外设直接与内存交互来减轻CPU负担,仅在数据传输的起始与终止时刻发出中断请求使CPU介入处理,实现了高效的内存访问操作。
同理,RDMA就是类似的一种在不同主机之间直接进行内存访问的技术。RDMA拓展了DMA的理念,显著优化了分布式系统中的数据传输效率。下图展示了RDMA与DMA技术的基本示意。
另一方面,因为 RDMA 涉及到主机间的数据传输,它又和传统的网络通信技术有所关联。
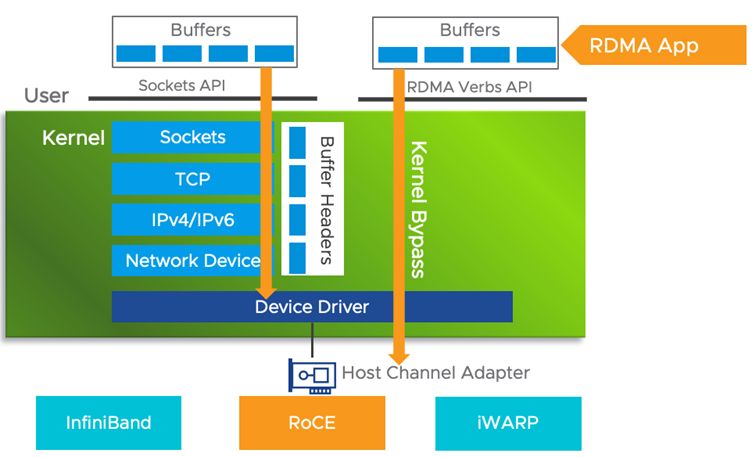
如下图所示,传统的 TCP/IP 网络通信中,数据需先从应用层缓存复制至内核空间的TCP协议栈缓冲区,继而传送至设备驱动层,最终到达网卡缓存。传输到另一台主机上时也需要反过来层层往上传输。多次内存复制操作不仅导致CPU频繁介入,造成约数十微秒的延迟,还大幅度消耗了CPU资源,影响了数据处理与计算任务的性能表现。
鉴于此,RDMA技术凭借内核旁路(Kernel Bypass) 与 零拷贝(Zero Copy) 策略,有效降低了通信延迟。其中,Kernel Bypass 通过提供专门的Verbs接口替代标准的TCP/IP Socket接口,允许应用程序在用户态直接执行数据传输任务,无须在用户态与内核态间切换,从而减少了上下文转换的开销。而 Zero Copy 则是指应用程序能够在不经过网络协议栈的情况下,直接经由缓冲区访问集群内的内存,避免了额外的内存复制步骤,进一步提升了效率与响应速度。
硬件实现
目前RDMA有三种不同的硬件实现,它们都可以使用同一套API来使用,但它们有着不同的物理层和链路层。(如下图所示)
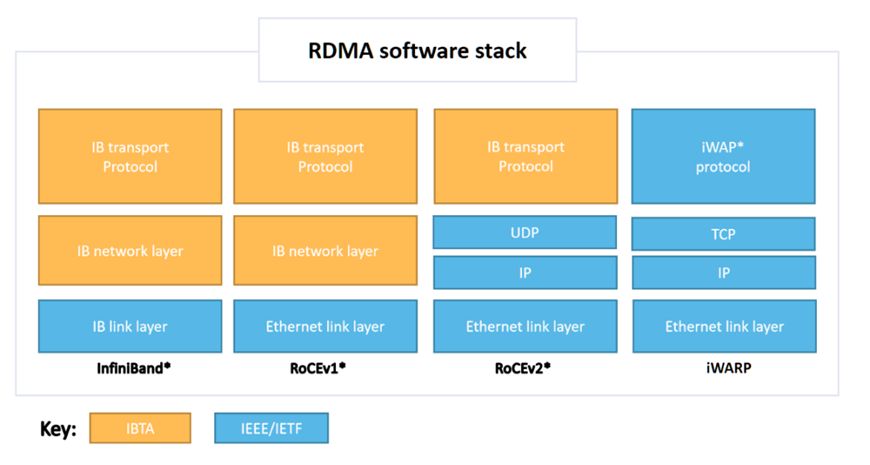
- InfiniBand(IB): 一种直接支持RDMA的新一代网络协议。对应的硬件实现则需要专用的 IB 网卡和 IB 交换机。由于从硬件级别保证了可靠传输,提供更高的带宽和更低的时延,但是成本高。
- RoCE:RDMA over Converged Ethernet。允许在标准以太网基础架构上使用RDMA,但是需要交换机支持无损以太网传输,网卡必须是支持RoCE的特殊NIC。消耗的资源比 iWARP 少,支持的特性比 iWARP 多。
- iWARP:Internet Wide Area RDMA Protocal。基于 TCP/IP 协议的 RDMA 技术,由 IEEE/IETF 标准定义。iWARP 支持在标准以太网基础设施上使用 RDMA 技术的同时不需要交换机支持无损以太网传输,但需要使用支持 iWARP 的网卡。但因为受 TCP 影响,性能稍差。
存储策略
现如今,AI大模型的发展变得如火如荼,为了构建通用型人工智能AI模型,往往需要存储大量的图像、视频、文本等多模态数据。因此,如何高效且节能地存储这些数据,也是构建大型AI集群的重要议题之一。
Meta在数据存储方面利用了Linux系统的FUSE API,结合他们在2021年公开的 Tectonic 分布式存储方案来实现的 GPU 的同步保存,以及 checkpoint 的存储和加载。
另一方面,Meta还与Hammerspace合作,共同开发并落地并行网络文件系统(pNFS)部署,以满足AI集群的开发者体验要求,此外还使工程师能够使用数千个 GPU 对作业执行交互式调试,因为环境中的所有节点都可以立即访问代码更改。
FUSE
FUSE,全称为Filesystem in Userspace,即用户空间中的文件系统。它是一个使得用户空间的程序能够实现一个文件系统,而不需要修改或重新编译操作系统内核的软件接口。在传统的Linux系统中,文件系统都是作为内核的一部分实现的,而FUSE则打破了这一限制,允许开发者在用户态(非特权级别)编写代码来定义文件系统行为,然后通过FUSE模块将其挂载到内核中,使得操作系统能够像访问任何其他文件系统一样访问它。
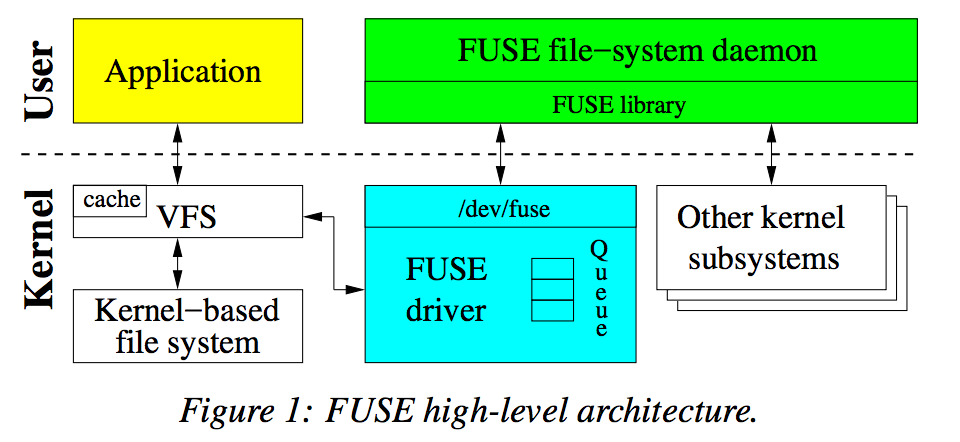
上图展示了FUSE架构的一个操作流程。当应用程序挂载FUSE文件系统,并发起系统调用时,虚拟文件系统(VFS)会将这些操作导向FUSE driver。驱动随即生成一个请求结构体,将此请求暂存于队列中,应用进程暂时进入等待状态。与此同时,FUSE守护进程(daemon)通过访问 /dev/fuse 设备接口,提取队列中的请求,并将相关操作通过管道转发至对应的文件系统(也在用户态)进行处理。一旦操作完成,守护进程将response写回 /dev/fuse,FUSE driver 则将此请求标记为已完成,从而使应用进程继续执行。
Tectonic
Tectonic 是 Meta 于 2021 年发表在FAST '21上的一篇名为《Facebook’s Tectonic Filesystem: Effificiency from Exascale》的论文中所介绍的服务于 Meta(原 FaceBook)的支持多租户的超大规模分布式文件系统。
起源
在 Tectonic 研发之前,Meta 的数据存储架构依赖于多种系统(如图所示),包括 HDFS(用于批处理和数据分析)、Haystack(存储 hot Blobs 数据)以及 f4。

这种多系统并存的模式虽然满足了不同数据类型的特定需求,但也引入了复杂性,增加了运维难度,并导致资源分配不均,效率低下。例如用于存储 Hot blobs 数据的 Haystack空有多余的磁盘空间但 IOPS 较高,没法做到高效的存储;而f4则相反,因为IOPS表现一般浪费了更优的存储效率。
面对上述挑战,Meta 设计并实现了 Tectonic 文件系统,旨在通过一个统一的平台解决存储效率和运维难题。Tectonic 的目标是在不牺牲性能的前提下,整合存储资源,提供对各种类型数据的支持,从而实现更高的资源利用率和更低的运维成本。
一个Tectonic集群的架构如下图所示:
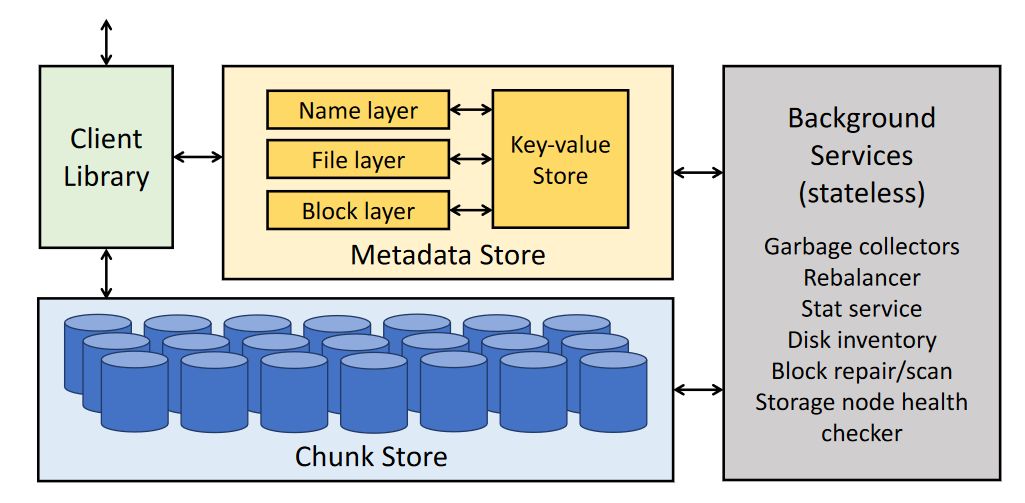
从架构我们能看到整个集群4部分组成:
- Client Library
- Metadata Store
- Chunk Store
- Background Services 后台服务。无状态,主要负责维护整个系统的一致性以及负载均衡监控
Chunk Store
Tectonic 的 Chunk Store 部分存储着大量作为基础的数据存储单元的 chunk。它在设计上有两个主要的特点:
- 存储Chunk数的能力可以随着存储节点的增加而线性扩展
- 分离Block、File、Directory等概念,只做到专注chunk的存储
这些特点使得 Tectonic具有高度的灵活性、优异的扩展潜力以及存储资源的高效利用,从而为大规模数据管理提供了坚实的基础。
Metadata Store
Tectonic 的 Metadata Store 构成了其设计的核心要件。特别是在处理EB量级数据存储场景下,元数据本身也非常庞大,因此要求元数据存储具备强大的横向扩展能力。针对此需求,Tectonic巧妙地将元数据抽象为简洁的键值(Key-Value, KV)模型,这一设计不仅促进了高水平的横向扩展性和负载均衡能力,还有效缓解了数据访问中的热点问题。
具体来说,将Metadata Store分为三层,如下表所示。

- Name:负责维护目录与目录元素(包括子目录及文件)之间的映射关系
- File:专注于文件与数据块(Block)的对应关系
- Block:建立数据块与存储块(chunk)的映射,并且Block层还承担着维护磁盘与数据块之间逆向映射的任务,以支持高效的物理寻址。
这样层级化的结构易于按需扩展,每个层级均可独立扩展,适应数据量的指数级增长;此外通过层次化索引可以减少查询路径,加速元数据检索,提高数据访问速度。
Parallel NFS
Meta 与 Hammerspace 的深度合作进一步促成了 Meta 定制的并行网络文件系统(Parallel Network File System, pNFS)的部署,该系统专为满足人工智能(AI)集群环境下开发者对于即时交互式调试的高度需求而设计,确保代码变更能够迅速生效。Tectonic 分布式文件系统与 Hammerspace 的融合,不仅巩固了 Meta 在大规模数据管理上的领导地位,还极大提升了研发迭代的敏捷性,实现了规模与效率的双赢。
传统的网络文件系统(NFS)架构由两个核心组件构成:一个作为文件系统提供者的服务器端,以及一个或多个挂载该文件系统的客户端。在这种架构中,存储资源被集中部署于服务器端。客户端若要访问存储设备上的文件,必须先通过网络通道与服务器建立连接,再由服务器中转接至目标文件,这一过程可视为带内访问。
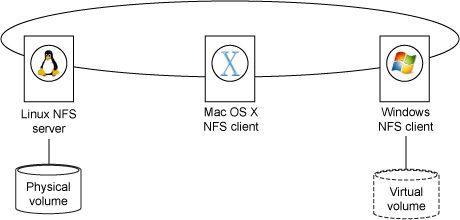
如上图所示,一台Linux服务器作为 NFS server 扮演着核心角色,负责托管和输出(采用NFS协议)一个或多个实际的文件系统卷。而Mac OS X与Windows则作为客户端,分别挂载并利用这些共享的文件系统资源。
当Windows客户端需要访问存储上的文件时,必须首先向Linux服务器发送请求以获取文件系统及其元数据/布局信息(layout),之后通过服务器间接完成数据读取。
显然,受制于网络带宽限制、存储容量以及处理器性能等因素,NFS在支持高性能计算(HPC)场景下表现不尽人意,难以充分满足高效数据处理的需求。
而pNFS,作为NFS的下一个修改版本version 4.1,整合了传统 NFS 的优势和并行I/O的高传输率的能力。允许客户端、服务器直接与存储器相连,客户端不必再通过服务器间接访问存储器,即实现了带外访问,从而规避了网络带宽瓶颈,显著增强了系统性能。
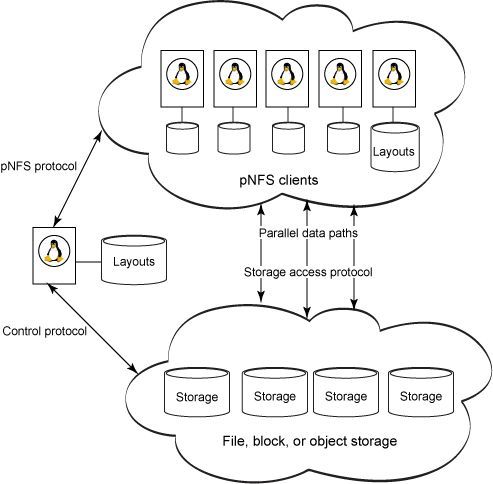
如上图所示,当客户端需要读写存储器数据时,首先通过pNFS 协议(pNFS Protocol)在 pNFS 服务器和客户机节点之间传输文件元数据并获得访问权限,然后通过对应的存储访问协议(Storage Access Protocol)指定客户机从数据仓库访问数据的方式,之后便可直接访问。在客户端对文件作出修改后,其会更新本地维护的布局信息副本,并最终同步所有变动回pNFS服务器。操作完毕,客户端在归还文件前,会提交所有剩余更新,将布局信息复归服务器,并执行文件关闭操作,以此确保数据的一致性和完整性。
性能优化
为了构建能够兼具高性能和易用性的大规模AI集群,Meta提出了一种逐步叠加的性能优化策略。具体来说首先快速地构建出一个切实可用的小型集群,对其进行优化和测试。随后不断在此基础上加大集群规模,并继续进行优化和测试,以找到大规模集群构建的瓶颈所在。
下图显示了大量 GPU 相互通信时 AllGather 的性能表现(以带宽利用率为指标,归一化至0-100)情况。
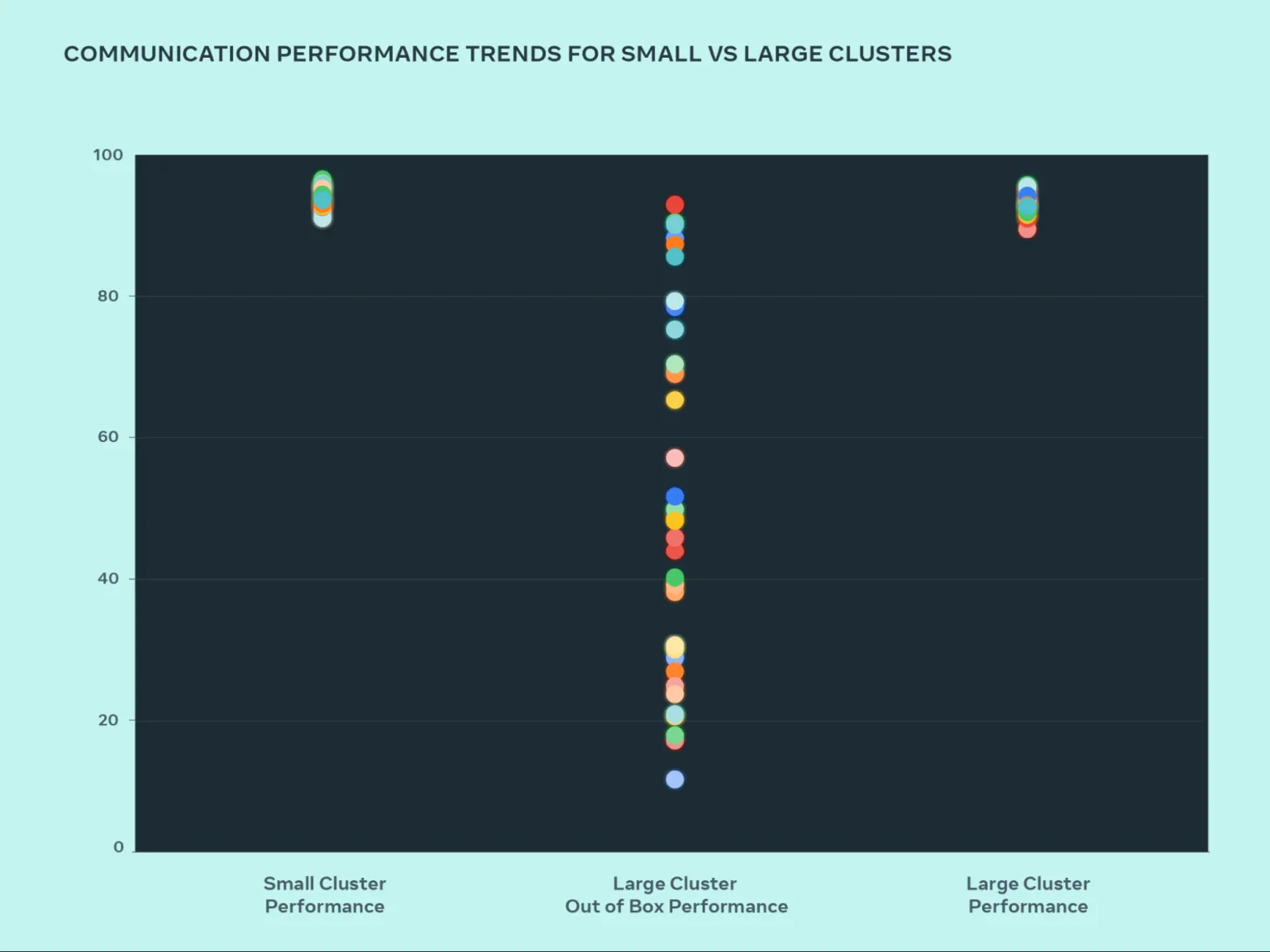
观察可知,小型集群的性能表现优异,通信带宽利用率自部署之初即稳定在90%以上,而未经调优的大型集群的性能利用率则呈现显著波动,从 10% 到 90% 不等。为了解决大型集群初期性能不佳的问题,针对大型集群的性能短板,Meta采取了系统性优化策略,涵盖软件、网络等多个层面,使得大型集群的性能利用率回升至90%以上的理想区间。
Meta的具体优化措施包括革新内部作业调度器(Job scheduler),通过优化网络拓扑设计减少了上层网络的流量拥堵,显著降低了通信延迟。此外,针对网络路由算法及NVIDIA的集合通信库NCCL进行了细致调优,以确保网络资源得到充分利用。这一系列针对性的改进举措,共同推动了大型集群实现性能的显著提升,使其能够达到与小型集群同等的高效能水平。