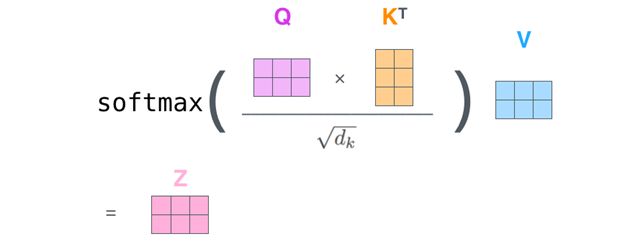Motivation | 起源 状态空间表示法 在现代控制理论 中,状态是指在一个动态系统 中可以用于决定系统状态 的最小数目 的变量的有序集合。而状态空间则是指该系统全部可能的状态的集合。
状态空间表示法即为一种将系统表示为一组输入、输出及状态 的数学模式,而输入、输出及状态之间的关系用多个一阶微分方程 来描述。一般地,考虑多输入多输出情况的时变系统 时,我们用向量形式表达:
x ˙ = f ( x , u , t ) y = g ( x , u , t ) \begin{aligned} \dot{\boldsymbol x}&=\boldsymbol{f}(\boldsymbol x,\boldsymbol u,t)\\ \boldsymbol y&=\boldsymbol{g}(\boldsymbol x,\boldsymbol u,t) \end{aligned} x ˙ y = f ( x , u , t ) = g ( x , u , t )
其中,x \boldsymbol x x u \boldsymbol u u y \boldsymbol y y x ˙ : = d x d t \dot{\boldsymbol x}:=\dfrac{\mathrm d\boldsymbol x}{\mathrm dt} x ˙ := d t d x
特别地,考虑线性系统 时,我们有:
x ˙ ( t ) = A ( t ) x ( t ) + B ( t ) u ( t ) y ( t ) = C ( t ) x ( t ) + D ( t ) u ( t ) \begin{aligned} \dot{\boldsymbol x}(t)&=\boldsymbol{A}(t)\boldsymbol x(t)+\boldsymbol{B}(t)\boldsymbol u(t)\\ \boldsymbol y(t)&=\boldsymbol{C}(t)\boldsymbol x(t)+\boldsymbol{D}(t)\boldsymbol u(t) \end{aligned} x ˙ ( t ) y ( t ) = A ( t ) x ( t ) + B ( t ) u ( t ) = C ( t ) x ( t ) + D ( t ) u ( t )
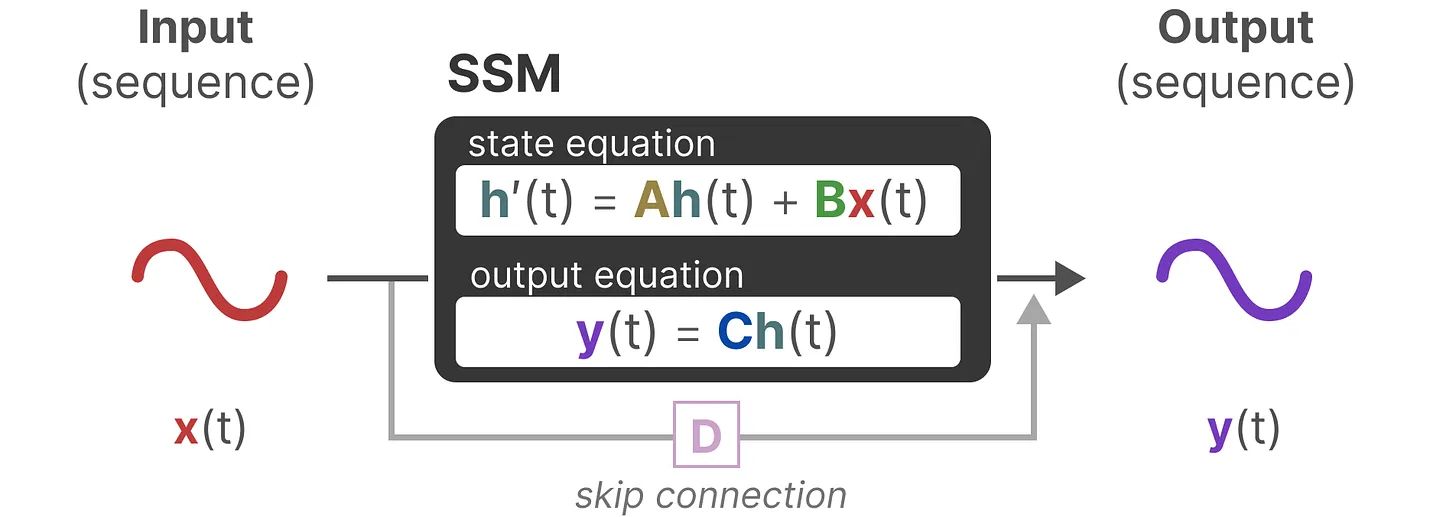
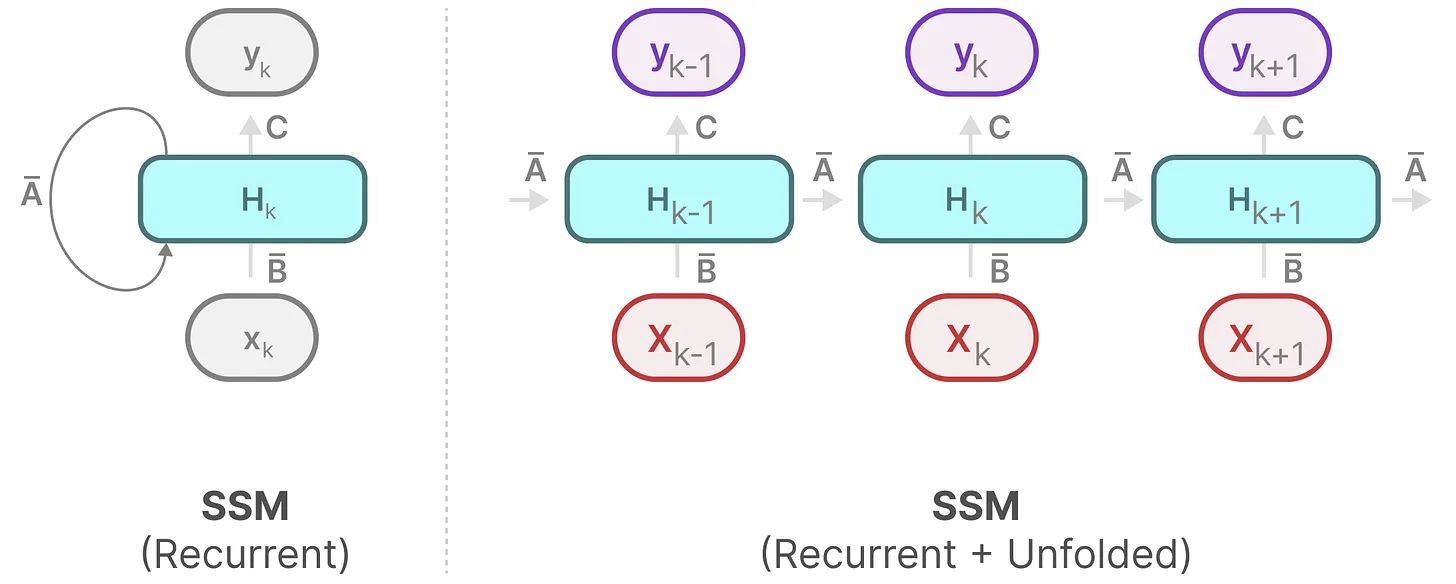
而状态空间模型(State Space Model,SSM)则是沿用了这种看待物理系统的视角,使用单输入单输出的线性时不变系统 来建模一个有输入有输出的机器学习模型,固定四个系数矩阵不变。如果采用机器学习中比较常用的数学符号 重新书写上述方程,即可得到:
h ˙ ( t ) = A h ( t ) + B x ( t ) y ( t ) = C h ( t ) + D x ( t ) \begin{aligned} \dot{\boldsymbol h}(t)&=\boldsymbol{A}\boldsymbol h(t)+\boldsymbol{B}x(t)\\ y(t)&=\boldsymbol{C}\boldsymbol h(t)+\boldsymbol{D}x(t) \end{aligned} h ˙ ( t ) y ( t ) = A h ( t ) + B x ( t ) = C h ( t ) + D x ( t )
其中h ( t ) ∈ R N \boldsymbol h(t)\in\mathbb R^N h ( t ) ∈ R N x ( t ) ∈ R x(t)\in\mathbb R x ( t ) ∈ R 1),A , C ∈ R N × N , B , D ∈ R N \boldsymbol {A},\boldsymbol {C}\in\mathbb R^{N\times N}, \boldsymbol {B},\boldsymbol {D}\in\mathbb R^{N} A , C ∈ R N × N , B , D ∈ R N N N N
更进一步地,沿用深度学习的思考方式, 输出步的D x ( t ) \boldsymbol{D}x(t) D x ( t ) y ( t ) = C h ( t ) y(t)=\boldsymbol{C}\boldsymbol h(t) y ( t ) = C h ( t )
另外,为了将输入从一维扩展到多维的情况,SSM通过对每一个维度都独立执行单值输入SSM的方式得到多输入多输出的SSM ,而不是传统线性控制理论中的多输入多输出系统那样。
微分方程的求解 事实上,该微分方程满足一阶线性非齐次微分方程 的形式,因此可以直接套公式求解得到:
h ( t ) = e A t ( B ∫ 0 t x ( τ ) e − A τ d τ + C ) \boldsymbol h(t)=e^{\boldsymbol At}\biggl(\boldsymbol B\int_{0}^tx(\tau)e^{-\boldsymbol A\tau}\mathrm d\tau+C\biggr) h ( t ) = e A t ( B ∫ 0 t x ( τ ) e − A τ d τ + C )
此处的非粗体C C C
给定初值h ( 0 ) \boldsymbol h(0) h ( 0 )
h ( t ) = h ( 0 ) e A t + B e A t ∫ 0 t x ( τ ) e − A τ d τ \boldsymbol h(t)=\boldsymbol h(0)e^{\boldsymbol At}+\boldsymbol Be^{\boldsymbol At}\int_{0}^tx(\tau)e^{-\boldsymbol A\tau}\mathrm d\tau h ( t ) = h ( 0 ) e A t + B e A t ∫ 0 t x ( τ ) e − A τ d τ
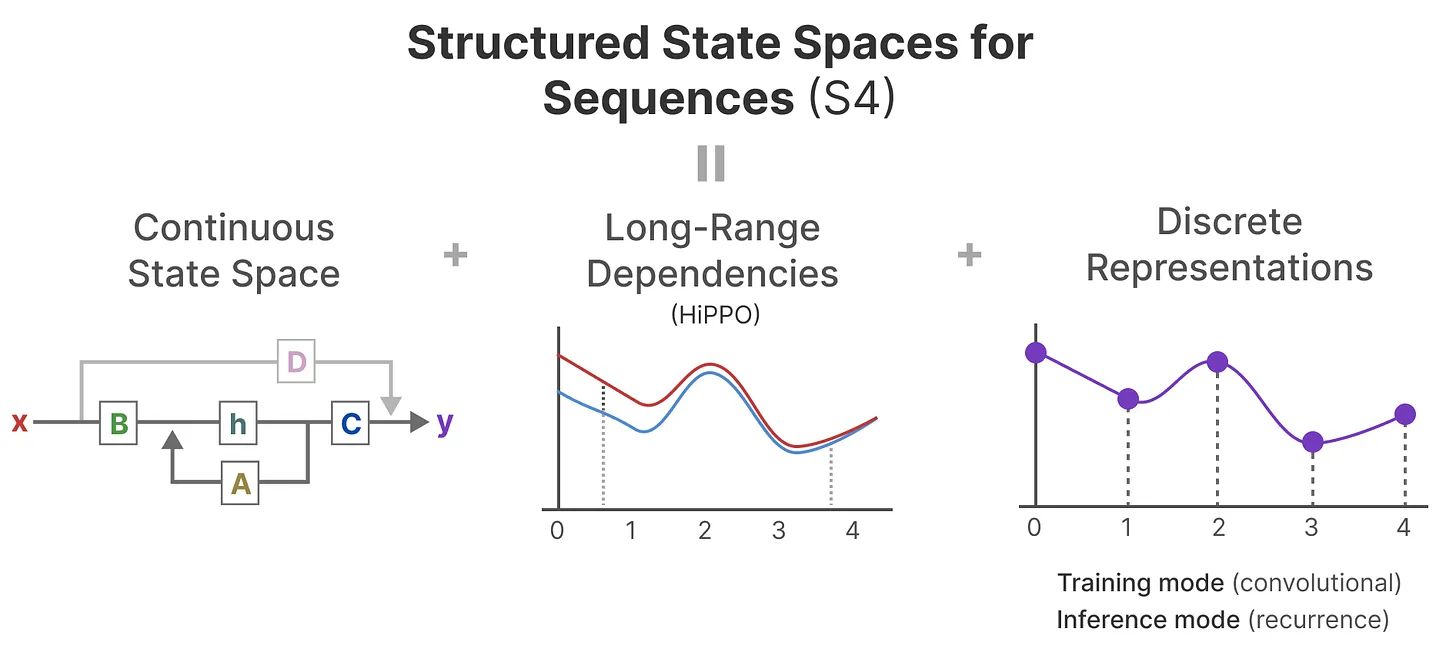
S4: 结构化SSM Efficiently Modeling Long Sequences with Structured State Spaces (arxiv.org)
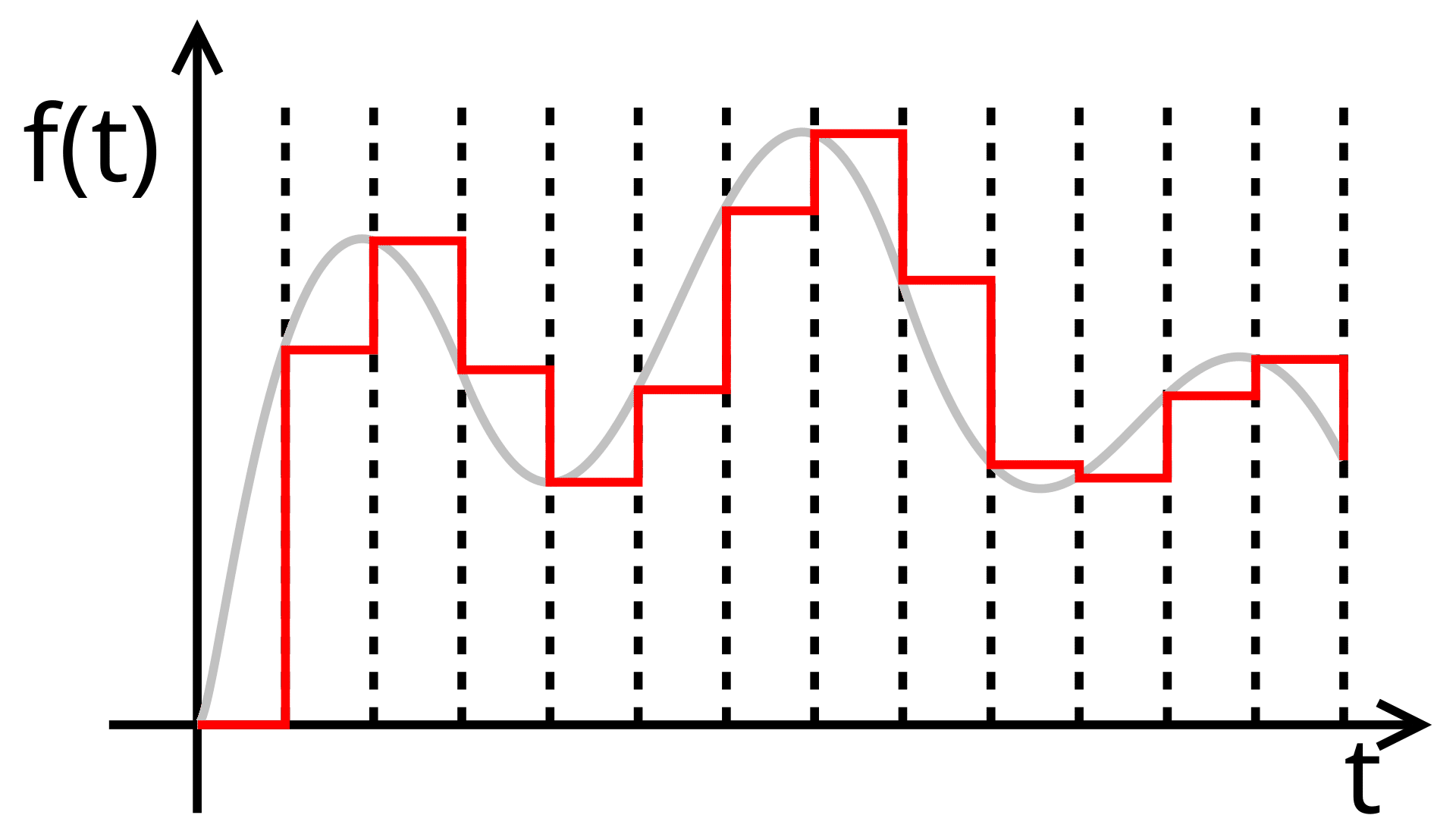
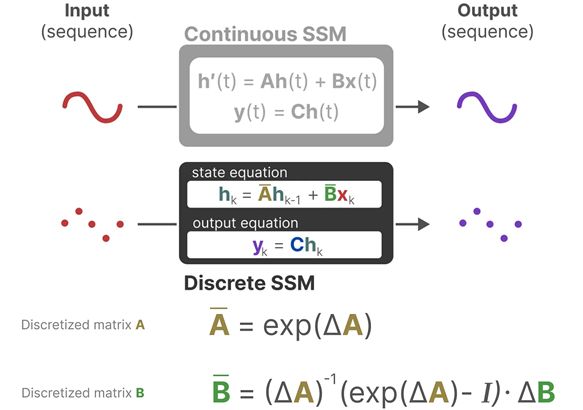
离散化处理 SSM的原始表达针对的是连续信号 ,而如果要将它视为机器学习模型,我们希望它同样可以作用于离散输入。实际上在工程中往往输入的也只是连续信号的采样 。
而处理离散值的一个最有效的方法就是利用 零阶保持技术(Zero-order hold technique) 将离散值转化为连续值。
如图所示,零阶保持将每一个时刻t t t t + Δ t+\Delta t + Δ x ( t + Δ ) = x ( t ) x(t+\Delta)=x(t) x ( t + Δ ) = x ( t )
从而我们有:
h ( t + Δ ) = h ( 0 ) e A ( t + Δ ) + B e A ( t + Δ ) ∫ 0 t + Δ x ( τ ) e − A τ d τ = e Δ A × [ h ( 0 ) e A t + B e A t ∫ 0 t x ( τ ) e − A τ d τ ] + B e A ( t + Δ ) ∫ t t + Δ x ( τ ) e − A τ d τ = e Δ A × h ( t ) + B e A ( t + Δ ) ∫ t t + Δ e − A τ d τ × x ( t ) = e Δ A × h ( t ) + A − 1 ( e Δ A − I ) B × x ( t ) = e Δ A × h ( t ) + ( Δ A ) − 1 ( e Δ A − I ) Δ B × x ( t ) : = A ‾ h ( t ) + B ‾ x ( t ) \begin{aligned} \boldsymbol h(t+\Delta)&=\boldsymbol h(0)e^{\boldsymbol A(t+\Delta)}+\boldsymbol Be^{\boldsymbol A(t+\Delta)}\int_{0}^{t+\Delta}x(\tau)e^{-\boldsymbol A\tau}\mathrm d\tau\\ &=e^{\Delta \boldsymbol A}\times\left[\boldsymbol h(0)e^{\boldsymbol At}+\boldsymbol Be^{\boldsymbol At}\int_{0}^{t}x(\tau)e^{-\boldsymbol A\tau}\mathrm d\tau\right]+\boldsymbol Be^{\boldsymbol A(t+\Delta)}\int_{t}^{t+\Delta}x(\tau)e^{-\boldsymbol A\tau}\mathrm d\tau\\ &=e^{\Delta \boldsymbol A}\times\boldsymbol h(t)+\boldsymbol Be^{\boldsymbol A(t+\Delta)}\int_{t}^{t+\Delta}e^{-\boldsymbol A\tau}\mathrm d\tau\times x(t)\\ &=e^{\Delta \boldsymbol A}\times\boldsymbol h(t)+\boldsymbol A^{-1}(e^{\Delta \boldsymbol A}-\boldsymbol I)\boldsymbol B\times x(t)\\ &=e^{\Delta \boldsymbol A}\times\boldsymbol h(t)+(\Delta\boldsymbol A)^{-1}(e^{\Delta \boldsymbol A}-\boldsymbol I)\Delta\boldsymbol B\times x(t)\\ :&=\overline{\boldsymbol A}\boldsymbol h(t)+\overline{\boldsymbol B} x(t) \end{aligned} h ( t + Δ ) : = h ( 0 ) e A ( t + Δ ) + B e A ( t + Δ ) ∫ 0 t + Δ x ( τ ) e − A τ d τ = e Δ A × [ h ( 0 ) e A t + B e A t ∫ 0 t x ( τ ) e − A τ d τ ] + B e A ( t + Δ ) ∫ t t + Δ x ( τ ) e − A τ d τ = e Δ A × h ( t ) + B e A ( t + Δ ) ∫ t t + Δ e − A τ d τ × x ( t ) = e Δ A × h ( t ) + A − 1 ( e Δ A − I ) B × x ( t ) = e Δ A × h ( t ) + ( Δ A ) − 1 ( e Δ A − I ) Δ B × x ( t ) = A h ( t ) + B x ( t )
也就是说,考虑离散情况就有:
对比RNN和CNN 离散化之后的SSM由于计算每一个时间步的隐状态变量都需要依靠上一时间步的内容,因此它在结构上是与 循环神经网络 RNN 类似的(如图所示)。
和 RNN 的前向传播过程(见下式)相比,SSM的系数(A ‾ \overline{A} A B ‾ \overline{B} B C C C A , B , C A,B,C A , B , C
RNN: h ( t ) = tanh ( U x ( t ) + W h ( t − 1 ) + b ) SSM: h ( t ) = A ‾ h ( t − 1 ) + B ‾ x ( t ) \begin{aligned} \text{RNN: }&\boldsymbol h^{(t)}=\operatorname{tanh}(\boldsymbol U\boldsymbol x^{(t)}+\boldsymbol W\boldsymbol h^{(t-1)}+\boldsymbol b)\\ \text{SSM: }&\boldsymbol h^{(t)}=\overline{\boldsymbol A}\boldsymbol h^{(t-1)}+\overline{\boldsymbol B}\boldsymbol x^{(t)} \end{aligned} RNN: SSM: h ( t ) = tanh ( U x ( t ) + W h ( t − 1 ) + b ) h ( t ) = A h ( t − 1 ) + B x ( t )
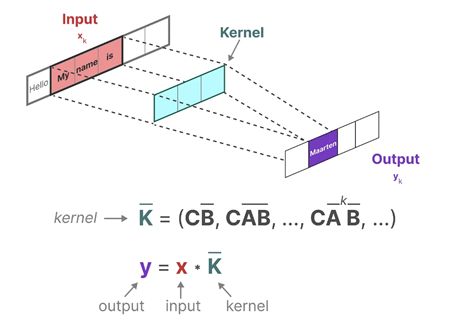
再和 CNN 作对比。如果我们需要计算第k k k A ‾ \overline{A} A B ‾ \overline{B} B C C C
y ( k ) = ( C B ‾ + C A B ‾ + ⋯ + C A k B ‾ ) ( x ( 0 ) x ( 1 ) ⋮ x ( k ) ) y^{(k)}=\big(\boldsymbol C\overline{\boldsymbol B}+\boldsymbol C\overline{\boldsymbol {AB}}+\cdots+\boldsymbol C\overline{\boldsymbol {A}^k\boldsymbol{B}}\big) \begin{pmatrix}\boldsymbol{x}^{(0)}\\\boldsymbol{x}^{(1)}\\\vdots\\\boldsymbol{x}^{(k)}\end{pmatrix} y ( k ) = ( C B + C AB + ⋯ + C A k B ) x ( 0 ) x ( 1 ) ⋮ x ( k )
该过程就可以视为是一维卷积 的过程。
由于SSM同时兼具了RNN 和 CNN 的特性,为了高效学习,我们可以在训练SSM时利用卷积模式实现并行计算,而推理(inference)时则利用递归模式对顺序输入依次进行输出。
HiPPO 矩阵 与RNN类似,SSM同样存在难以捕捉长期依赖的问题,这导致模型当前的隐状态只和最近几个时间步的输入强相关,而对更久的输入不再敏感甚至遗忘。
为了解决这个问题,一个有效的方法是“利用多项式函数逼近输入信号 ”。特别地,这里利用 Orthogonal Polynomials (正交多项式)来在线 对输入信号进行投影 。
例如,t t t d d d P i ( t ) P_i(t) P i ( t ) d d d c i c_i c i
x ≤ t ( t ) ≈ ∑ i = 1 d c i P i ( t ) x_{\leq t}(t)\approx \sum_{i=1}^dc_iP_i(t) x ≤ t ( t ) ≈ i = 1 ∑ d c i P i ( t )
而
c i = ∫ 0 t x ( τ ) P i ( τ ) w ( τ ) d τ ∫ 0 t P i 2 ( τ ) w ( τ ) d τ c_i=\dfrac{\int_0^t\boldsymbol x(\tau)P_i(\tau)w(\tau)\mathrm d\tau}{\int_0^t P_i^2(\tau)w(\tau)\mathrm d\tau} c i = ∫ 0 t P i 2 ( τ ) w ( τ ) d τ ∫ 0 t x ( τ ) P i ( τ ) w ( τ ) d τ
式中w ( τ ) w(\tau) w ( τ ) P i ( t ) P_i(t) P i ( t ) 两两正交 ,其中定义在区间( a , b ) (a,b) ( a , b )
⟨ P i , P j ⟩ = ∫ a b P i ( x ) P j ( x ) w ( x ) d x \langle P_i,P_j\rangle=\int_a^bP_i(x)P_j(x)w(x)\;\mathrm dx ⟨ P i , P j ⟩ = ∫ a b P i ( x ) P j ( x ) w ( x ) d x
假设我们取隐状态向量h \boldsymbol h h x \boldsymbol x x 系数 ,为了实现系数的在线更新 ,HiPPO的作者利用状态空间方程来表示这个过程,通过实验最终给出了可以在各种权函数上成立的状态更新矩阵A A A
H i P P O M a t r i x = A = [ A n k ] = { 0 , n < k n + 1 , n = k ( 2 n + 1 ) 1 / 2 ( 2 k + 1 ) 1 / 2 , n > k \mathbf{HiPPO\;Matrix}=\boldsymbol A=[A_{nk}]= \begin{cases} 0,&n\lt k\\ n+1,&n=k\\ (2n+1)^{1/2}(2k+1)^{1/2},&n>k \end{cases} HiPPO Matrix = A = [ A nk ] = ⎩ ⎨ ⎧ 0 , n + 1 , ( 2 n + 1 ) 1/2 ( 2 k + 1 ) 1/2 , n < k n = k n > k
从而在 S4 中,矩阵A A A
HiPPO: Recurrent Memory with Optimal Polynomial Projections (neurips.cc)
矩阵分解 S4 的作者为了更进一步减轻计算开销,还对矩阵进行了 Normal Plus Low-Rank (NPLR) 分解:
A = V Λ V ∗ − P Q ⊤ = V ( Λ − ( V ∗ P ) ( V ∗ Q ) ∗ ) V ∗ \boldsymbol{A=V\Lambda V^{*}-PQ^\top=V(\Lambda-(V^*P)(V^*Q)^*)V^*} A = V Λ V ∗ − P Q ⊤ = V ( Λ − ( V ∗ P ) ( V ∗ Q ) ∗ ) V ∗
无限卷积核 待更
S6: Mamba Mamba: Linear-Time Sequence Modeling with Selective State Spaces (arxiv.org)
S4 所使用的状态方程原型是一个线性时不变系统,因此这限制了规定 SSM中的三个矩阵A ‾ \overline{A} A B ‾ \overline{B} B C C C
针对这一问题,Mamba的解决办法是,相比SSM压缩所有历史记录,mamba设计了一个简单的选择机制,通过“函数化SSM的矩阵 ”,让模型对信息有选择性处理,以便关注或忽略特定的输入。简而言之,就是使得原来的线性时不变系统变为了时变系统。
函数化SSM矩阵 具体来说,Mamba 的作者通过将B , C , Δ B,C,\Delta B , C , Δ
与 S4 相比,其算法的更改如下:
其中,B B B L L L D D D N N N
值得注意的是,此处的A A A (D,N),但实际上这是对角化 带来的存储压缩优势,在实际计算时,对每一个维度 都构建一个N × N N\times N N × N 将每一个维度都视为一个单输入 SSM 来看待 ,而不是传统线性控制理论中的多输入多输出型线性系统。也因此,所得到的隐状态的形状应该是 (D,N) 。
另外,对于数据驱动的矩阵B , C B,C B , C (B,L,D,N) 形状的矩阵,而是线性映射到 (B,L,N) ,后续通过与Δ \Delta Δ B ‾ \overline B B B ‾ \overline B B D 这个轴了。由于Δ \Delta Δ A ‾ \overline A A
对角化矩阵 前面我们提到了对矩阵A A A
待更
并行扫描算法 由于原本训练好后即静态的矩阵都已经被修改成数据依赖的了,这就导致SSM可以无缝转为卷积操作的这种优良特性被打破。因此也就无法利用 CNN 策略实现训练时的并行计算,只能再次遵循 RNN 的模式进行训练。为了在Mamba上实现并行化,作者引入了并行扫描 (parallel scan) 算法使得并行化成为可能。
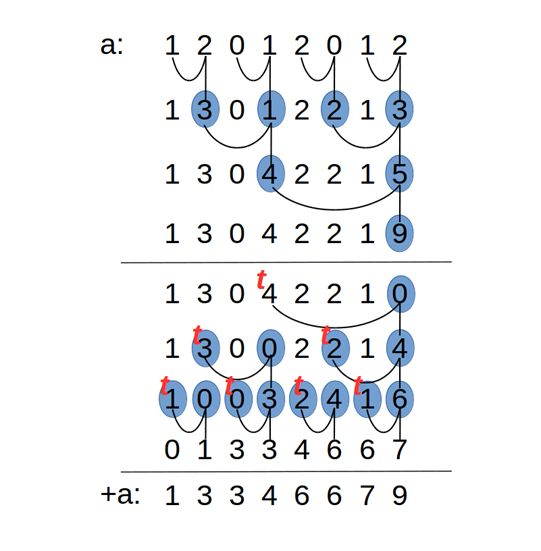
具体来说,Mamba中的并行扫描算法源于 并行计算中经典的并行前缀和(prefix sum) 。设输入数组[ x 0 , x 1 , ⋯ , x n ] [x_0, x_1,\cdots,x_n] [ x 0 , x 1 , ⋯ , x n ] 满足分配率 的二元操作⊕ \oplus ⊕ [ x 0 , x 0 ⊕ x 1 , ( x 0 ⊕ x 1 ) ⊕ x 2 , ⋯ , ⨁ i = 0 n x n ] [x_0,x_0\oplus x_1, (x_0\oplus x_1)\oplus x_2,\cdots, \bigoplus_{i=0}^nx_n] [ x 0 , x 0 ⊕ x 1 , ( x 0 ⊕ x 1 ) ⊕ x 2 , ⋯ , ⨁ i = 0 n x n ]
很容易得到该算法的一个链式/串式的递归方法:y i ← y i − 1 ⊕ x i y_i\leftarrow y_{i-1}\oplus x_i y i ← y i − 1 ⊕ x i O ( n ) O(n) O ( n ) 二叉树 则可以实现一定程度的并行计算。相关的方法有Kogge-Stone算法、Brent-Kung算法、 Hillis-Steele算法和Blelloch算法。其中 Mamba 借鉴的则是 Blelloch 算法。
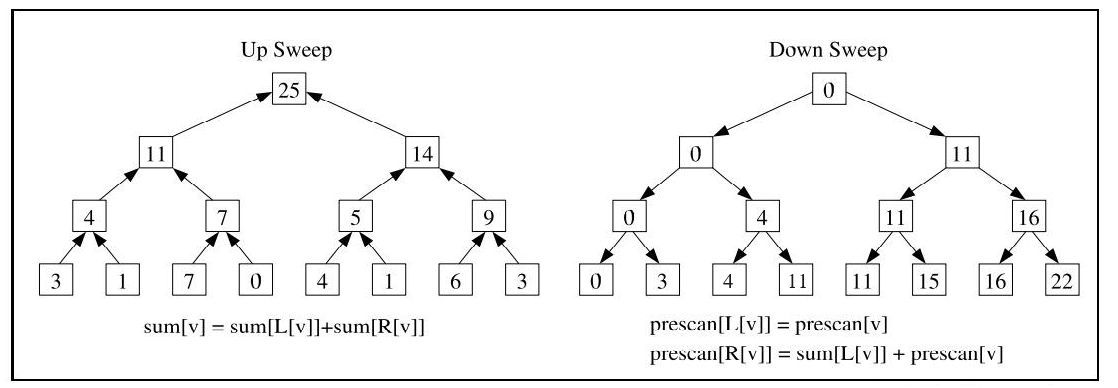
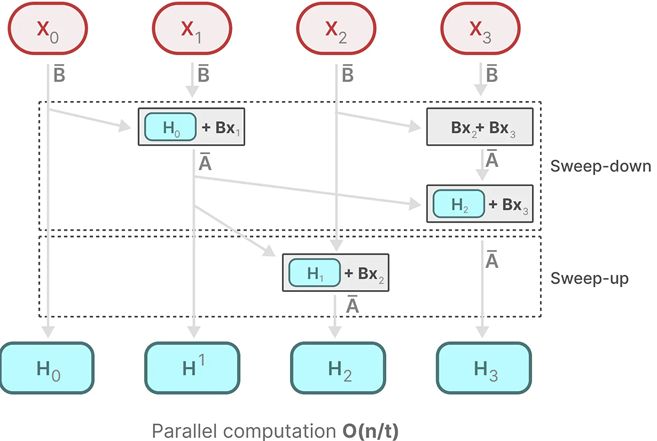
如上图所示,Blelloch 算法主要分为两个阶段:Up-Sweep 和 Down-Sweep。
Up-Sweep阶段 :对n n n 两两组合 计算累加和,然后将得到的n / 2 n/2 n /2 Down-Sweep阶段 :将根节点置零,然后从根节点开始,向下进行计算:右节点赋值为左节点加上根节点的值,左节点赋值为当前的根节点。计算完毕后,末尾补上上一阶段得到的总的累计和(或者整体左移,去掉开头的0)即可得到输出。这两个阶段除了总累计和需要一个单位的额外存储,其他的计算都可以在数组内原地计算(见下面的示例),空间复杂度为O ( 1 ) O(1) O ( 1 ) O ( log n ) O(\log n) O ( log n )
在 Mamba 中,作者假设执行操作的顺序与关联属性无关。因此,我们可以分段计算序列并迭代 地组合。其中定义了⊕ \oplus ⊕
( A ( t ) , B ( t ) x ( t ) ) ⊕ ( A ( t + ! ) , B ( t + 1 ) x ( t + 1 ) ) = ( A ( t ) A ( t + 1 ) , A ( t + 1 ) B ( t ) x ( t ) + B ( t + 1 ) x ( t + 1 ) ) (A^{(t)},\;B^{(t)}x^{(t)})\oplus(A^{(t+!)},\;B^{(t+1)}x^{(t+1)})=(A^{(t)}A^{(t+1)},\;A^{(t+1)}B^{(t)}x^{(t)}+B^{(t+1)}x^{(t+1)}) ( A ( t ) , B ( t ) x ( t ) ) ⊕ ( A ( t + !) , B ( t + 1 ) x ( t + 1 ) ) = ( A ( t ) A ( t + 1 ) , A ( t + 1 ) B ( t ) x ( t ) + B ( t + 1 ) x ( t + 1 ) )
使用 Blelloch 算法实现并行。如下图所示:
如果令 执行任务的处理器或计算单元的数量 为t t t O ( n / t ) O(n/t) O ( n / t )
相关链接:
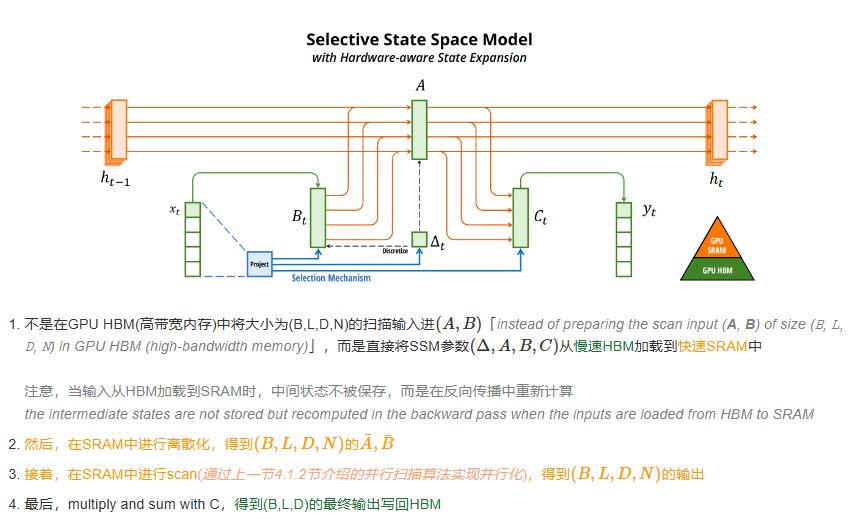
第十一章:前缀扫描 - 李理的博客 Hillis Steele Scan(并行前缀扫描算法) | 码农参考 NVIDIA CUDA 高度并行处理器编程(七):并行模式:前缀和_cuda前缀和-CSDN博客 Mamba.py:扫描和并行扫描 - 知乎 CUDA-扫描算法 | Junhui’s Journal (ashburnlee.github.io) 硬件感知设计 另一方面,为了让传统的 SSM 在现代 GPU 上也能高效计算,Mamba还沿用了其作者之前的论文中所介绍的Flash Attention技术。具体而言就是限制需要从 DRAM 到 SRAM 的次数(通过内核融合kernel fusion来实现),避免一有个结果便从SRAM写入到DRAM,而是待SRAM中有一批结果再集中写入DRAM中,从而降低来回读写的次数。在更高速的SRAM内存中执行离散化和递归操作,再将输出写回HBM((high-bandwidth memory )。
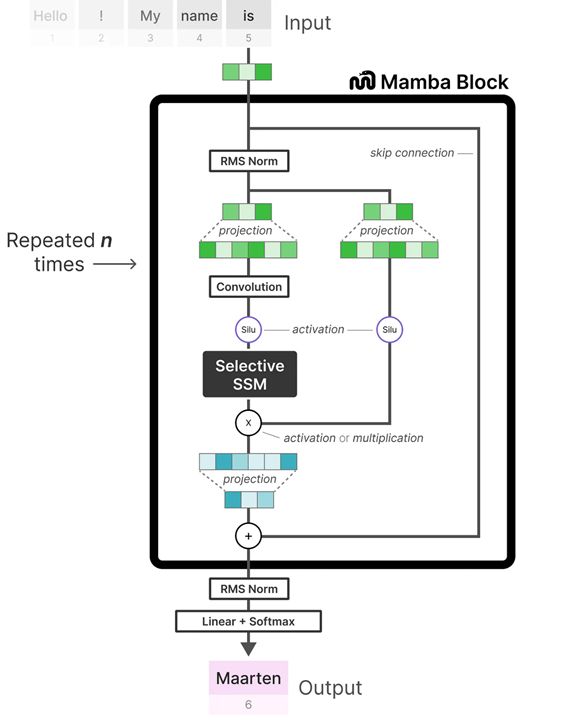
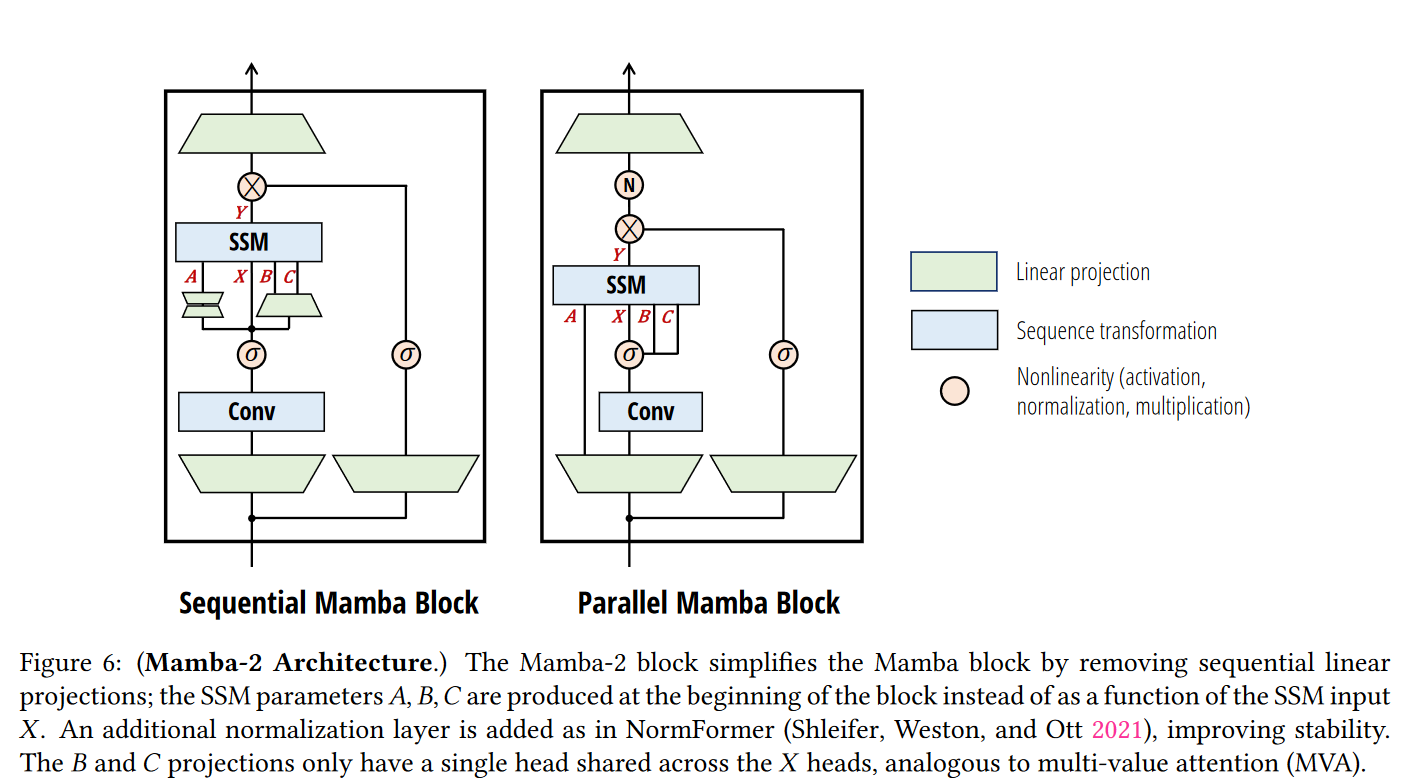
Mamba Block 将大多数 SSM 架构比如 H3 的基础块,与现代神经网络比如 Transformer 中普遍存在的门控MLP 相结合,组成新的Mamba块,重复这个块,与归一化和残差连接 (相当于原来的D D D
其中,线性投影层(Projection)将输入的 embedding 的维度进行调整(通常是增大维度),以便让模型能够处理更高维度的特征空间,从而捕获更细致、更复杂的特征。而后经过的 卷积层(Convolution) 则负责提取局部的短距离特征(此处是1维卷积),与之后负责捕捉长期依赖的SSM互为补充,确保在进入 SSM 之前,序列中的每个 token 已经考虑到了其相邻 token 的信息,解决了模型单独地处理每个 token,而没有考虑了局部上下文的问题。
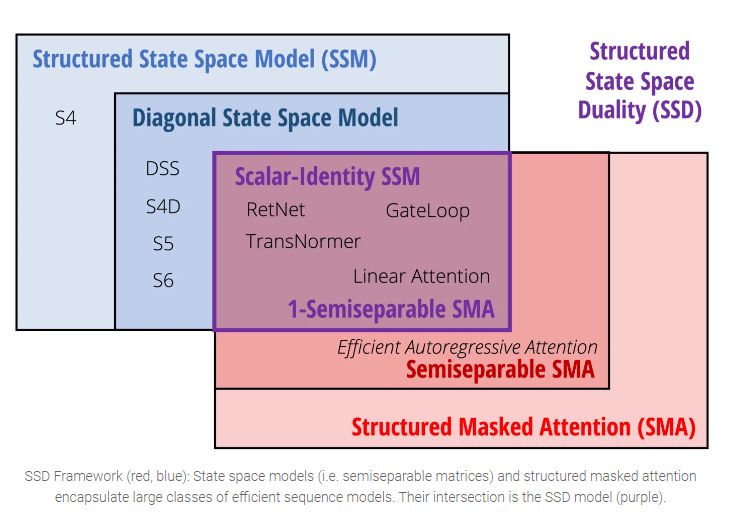
SSD: Mamba2 Paper:Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality Blog | Tri Dao
Mamba 的出现似乎抓住了连续系统、卷积网络和循环神经网络的本质,但是在它在概念层面 上仍然与如今序列模型大规模使用的变体注意力机制有所脱节,不仅如此,从计算的角度 来看,它的硬件效率仍然远低于注意力等机制。
为了解决以上问题,Mamba的作者进一步提出了结构化状态空间对偶 (structured state space duality ,SSD)的概念,包括 作为神经网络构建的SSD Model、在理论上推导SSM和Attention关系的 SSD Framework 和 用于高效计算的 SSD Algorithm。
SSD层的前向计算 与 Mamba-1 相比,SSD Layer 直接做了减法,令原本需要N N N A ∈ R N × N \mathbf A\in\mathbb R^{N\times N} A ∈ R N × N N N N 对角元素都为相同的值 ,从而在t t t a ( t ) a^{(t)} a ( t ) A \bf A A
而对与D D D 多头SSM 的说法。在这种语境下维度D D D
Y ( T , D ) = S S M ( A ( T , … ) , B ( T , N ) , C ( T , N ) ) ( X ( T , D ) ) \mathbf Y^\mathtt{(T,D)} = \mathsf{SSM}(\mathbf A^\mathtt{(T,…)}, \mathbf B^\mathtt{(T,N)}, \mathbf C^\mathtt{(T,N)})(\mathbf X^\mathtt{(T,D)}) Y ( T , D ) = SSM ( A ( T , … ) , B ( T , N ) , C ( T , N ) ) ( X ( T , D ) )
这里的上标表示的是数据的尺寸形状,如Y ( T , D ) \mathbf Y^\mathtt{(T,D)} Y ( T , D ) Y ∈ R T × D \mathbf Y\in\mathbb R^{T\times D} Y ∈ R T × D T T T D D D
注意,A , B , C \bf A,B,C A , B , C
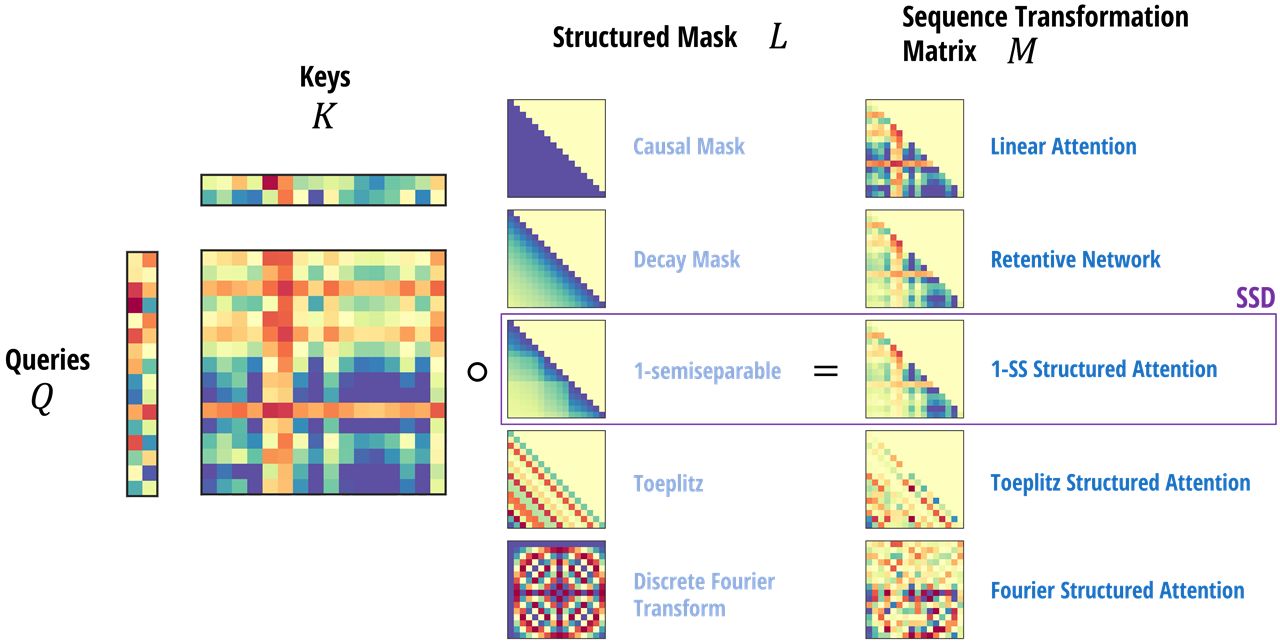
当表达式中的 (...) 不同时,代表不同类型的 SSM:
... = (N,N) 对应的就是传统的 SSM... = (N)对应的就是对角化的 SSM(或其他结构化SSM,例如对角矩阵分解)... = () 对应的就是 SSD特别地,如果令矩阵L ∈ R ( T , T ) \mathbf L\in\mathbb R^{\mathtt{(T,T)}} L ∈ R ( T , T )
L = [ 1 a 1 1 a 2 a 1 a 2 1 ⋮ ⋮ ⋱ ⋱ a T − 1 … a 1 a T − 1 … a 2 … a T − 1 1 ] \mathbf L = \begin{bmatrix} 1 & \\ a_1 & 1 & \\ a_2a_1 & a_2 & 1 \\ \vdots & \vdots & \ddots & \ddots \\ a_{\mathtt{T}-1}\dots a_1 & a_{\mathtt{T}-1}\dots a_2 & \dots & a_{\mathtt{T}-1} & 1 \\ \end{bmatrix} L = 1 a 1 a 2 a 1 ⋮ a T − 1 … a 1 1 a 2 ⋮ a T − 1 … a 2 1 ⋱ … ⋱ a T − 1 1
再定义矩阵M \mathbf M M
M = L ∘ C B ⊤ ∈ R ( T , T ) \mathbf M = \mathbf L \circ \mathbf{C B}^\top \in \mathbb{R}^{\mathtt{(T,T)}} M = L ∘ CB ⊤ ∈ R ( T , T )
那么,这样的一个矩阵就是在单个SSM头下的序列变换 x ∈ R ( T ) → y ∈ R ( T ) \boldsymbol x\in\mathbb R^{\mathtt{(T)}}\to\boldsymbol y\in\mathbb R^{\mathtt{(T)}} x ∈ R ( T ) → y ∈ R ( T ) y = M x \boldsymbol y=\mathbf M\boldsymbol x y = M x
有趣的是,如果令L \mathbf L L a t = 1 a_t=1 a t = 1 L \mathbf L L causal mask ),于是上式与因果线性注意力(causal linear attention )的公式就完全一致了!仅仅只是变量名不同而已!
Y = ( L ∘ Q K ⊤ ) V \mathbf Y = (\mathbf L \circ \mathbf{Q K}^\top)\mathbf V Y = ( L ∘ QK ⊤ ) V
所谓的对偶性 就是指原来遵循RNN模式的 SSM 前向可以“对偶”地表达成和注意力机制相似的矩阵乘法形式。
可见,scalar-times-identity structure on A \bf A A
状态空间对偶框架 本节将证明为什么 SSM 的计算过程可以表示成矩阵变换 的形式,以及该形式和注意力机制的联系,最终外推和泛化,总结了 SSM 和 Transformer 的关联,从而提出 SSD Framework。
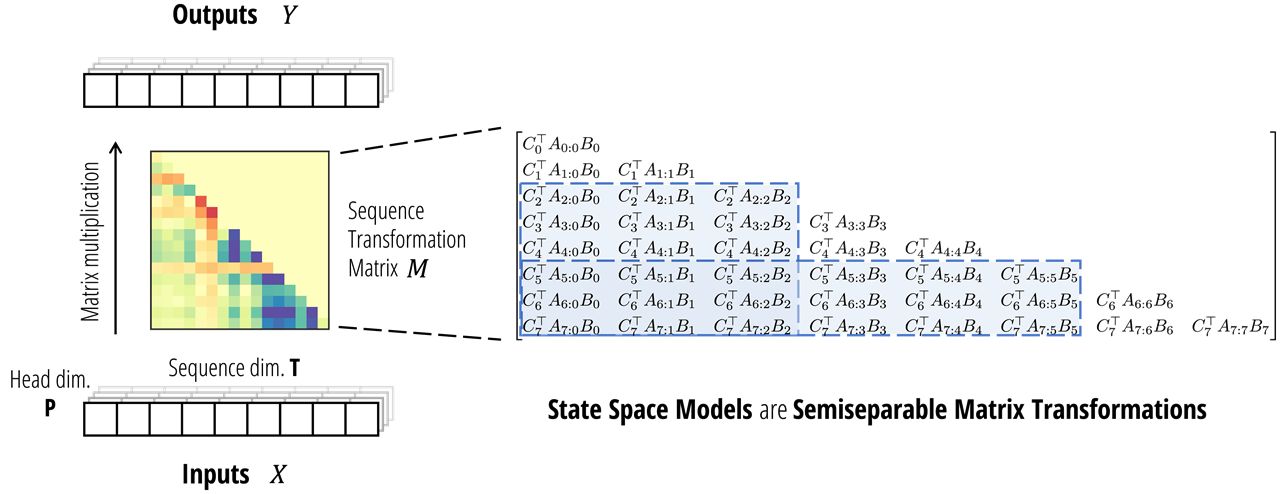
SSM 角度的理解 与传统 RNN 的非线性计算不同,考虑单个头的前向过程y = S S M ( A , B , C ) ( x ) \boldsymbol y = \mathsf{SSM}(\mathbf A, \mathbf B, \mathbf C)(\boldsymbol x) y = SSM ( A , B , C ) ( x ) y = M x \boldsymbol y=\mathbf M\boldsymbol x y = M x M \bf M M
[ C 0 ⊤ B 0 C 1 ⊤ A 1 B 0 C 1 ⊤ B 1 C 2 ⊤ A 2 A 1 B 0 C 2 ⊤ A 2 B 1 C 2 ⊤ B 2 ⋮ ⋮ ⋱ ⋱ C T ⊤ A T − 1 … A 1 B 0 C T ⊤ A T − 1 … A 2 B 1 … C T ⊤ A T − 1 B T − 2 C T ⊤ B T − 1 ] \begin{bmatrix} C_0^\top B_0 & \\ C_1^\top A_1 B_0 & C_1^\top B_1 & \\ C_2^\top A_2A_1 B_0 & C_2^\top A_2 B_1 & C_2^\top B_2 \\ \vdots & \vdots & \ddots & \ddots \\ C_\mathtt{T}^\top A_{\mathtt{T}-1}\dots A_1 B_0 & C_\mathtt{T}^\top A_{\mathtt{T}-1}\dots A_2 B_1 & \dots & C_\mathtt{T}^\top A_{\mathtt{T}-1} B_{\mathtt{T}-2} & C_\mathtt{T}^\top B_{\mathtt{T}-1} \\ \end{bmatrix} C 0 ⊤ B 0 C 1 ⊤ A 1 B 0 C 2 ⊤ A 2 A 1 B 0 ⋮ C T ⊤ A T − 1 … A 1 B 0 C 1 ⊤ B 1 C 2 ⊤ A 2 B 1 ⋮ C T ⊤ A T − 1 … A 2 B 1 C 2 ⊤ B 2 ⋱ … ⋱ C T ⊤ A T − 1 B T − 2 C T ⊤ B T − 1
显然它是一个下三角矩阵,当i < j i < j i < j M i j = 0 M_{ij} = 0 M ij = 0
M i j = C i ⊤ A i : j × B j : = C i ⊤ A i … A j + 1 B j M_{ij} = C_i^\top A_{i:j}^\times B_j := C_i^\top A_i \dots A_{j+1} B_j M ij = C i ⊤ A i : j × B j := C i ⊤ A i … A j + 1 B j
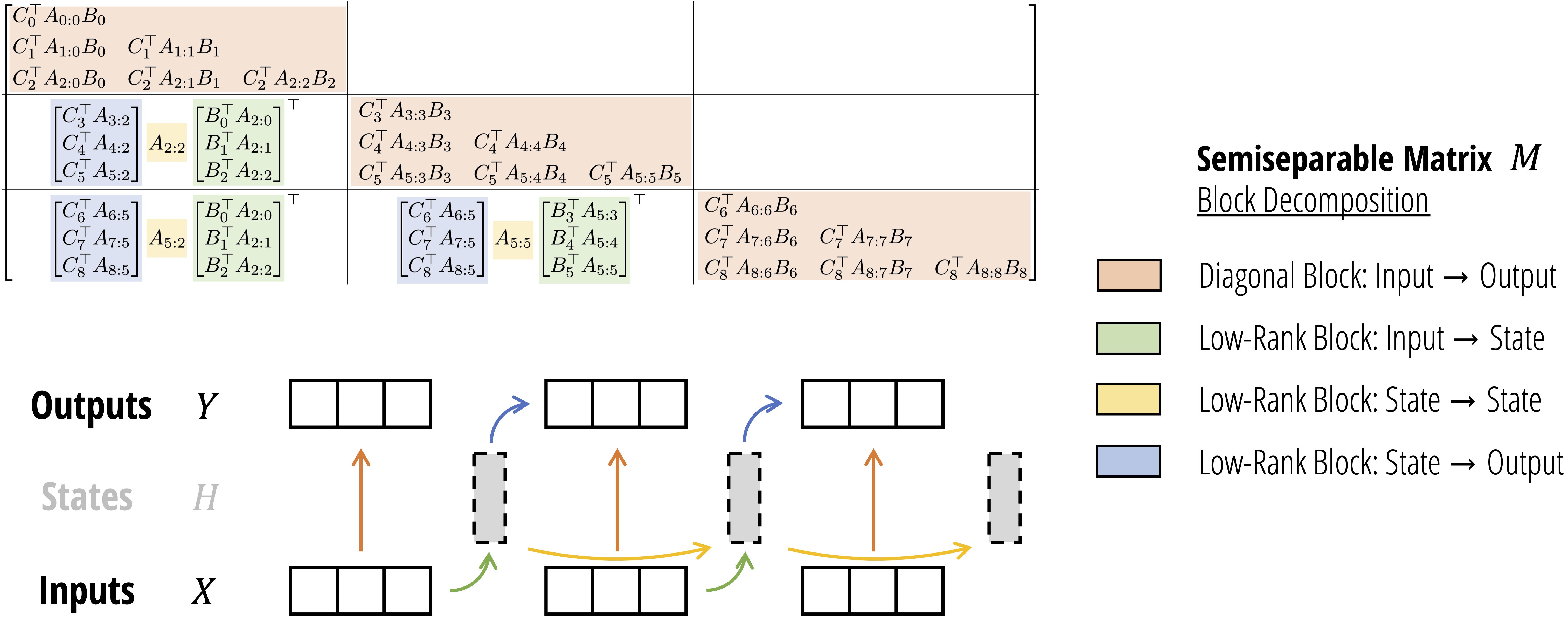
实际上,M \bf M M 半可分离(Semiseparable) 矩阵,这类矩阵已经在工程和计算线性代数的其他领域进行了研究。
定义 :一个(下)三角矩阵称为 N-semiseparable ,当且仅当其严格下三角部分(即下三角部分去掉对角线)的任意子矩阵的秩不超过N N N N N N
Semiseparable矩阵的一个重要性质就是虽然完整矩阵有O ( T 2 ) O(T^2) O ( T 2 ) O ( N T ) O(NT) O ( NT )
当 scalar-times-identity structure on A \bf A A
C i ⊤ A i : j × B j = A i : j × ⋅ ( C i ⊤ B j ) C_i^\top A_{i:j}^\times B_j = A_{i:j}^\times \cdot (C_i^\top B_j) C i ⊤ A i : j × B j = A i : j × ⋅ ( C i ⊤ B j )
从而导出M = L ∘ C B ⊤ \mathbf M = \mathbf L \circ \mathbf{C B}^\top M = L ∘ CB ⊤
Attention 角度的理解
在 Transformer 中,Self Attention 层作为主要部件占用了较大的计算复杂度。回顾其计算公式:
softmax ( Q K ⊤ d ) V \begin{aligned} \operatorname{softmax}\left(\frac{QK^\top }{\sqrt{d}}\right)V \end{aligned} softmax ( d Q K ⊤ ) V
其中的Q K ⊤ QK^\top Q K ⊤ 矩阵乘法 时,会产生O ( T 2 ) O(T^2) O ( T 2 ) T T T Q , K Q,K Q , K
如今已经有很多研究尝试将注意力机制的二次复杂性计算代价降到线性。在Mamba2中,作者沿用了 《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》的思路,尝试用更一般的形式来刻画注意力机制,即对于任何Y = f ( Q K ⊤ ) ⋅ V Y = f(QK^\top) \cdot V Y = f ( Q K ⊤ ) ⋅ V
如下所示:
Y = f ( Q K ⊤ ) ⋅ V = ψ ( Q ) ψ ( K ) ⊤ ⋅ V Let Q ← ψ ( Q ) , K ← ψ ( K ) then Y = ( Q K ⊤ ) ⋅ V \begin{aligned} Y&=f(QK^\top)\cdot V\\ &=\psi(Q)\psi(K)^\top\cdot V\\\\ \text{Let } Q&\leftarrow\psi(Q),\;K\leftarrow\psi(K)\\ \text{then }Y&=(QK^\top)\cdot V \end{aligned} Y Let Q then Y = f ( Q K ⊤ ) ⋅ V = ψ ( Q ) ψ ( K ) ⊤ ⋅ V ← ψ ( Q ) , K ← ψ ( K ) = ( Q K ⊤ ) ⋅ V
上式的结果还可以进一步通过矩阵乘积的结合律将计算降到线性,即Y = Q ⋅ ( K ⊤ V ) Y=Q\cdot (K^\top V) Y = Q ⋅ ( K ⊤ V )
但是,如果考虑带掩码的注意力机制(设掩码矩阵为L L L
Y = ( L ∘ Q K ⊤ ) ⋅ V Y = (L \circ Q K^\top)\cdot V Y = ( L ∘ Q K ⊤ ) ⋅ V
这使得问题变得复杂,不再能使用结合律以降低复杂度。不过 Mamba2 的作者通过理论推导,得出任意带掩码的注意力机制,都可以表示为4个张量的缩并 (Contraction)。从而得到具有线性复杂度的表达式:
Y = Q ⋅ c u m s u m ( K ⊤ V ) Y = Q \cdot \mathsf{cumsum}(K^\top V) Y = Q ⋅ cumsum ( K ⊤ V )
最终,作者提出了 Structured masked attention (SMA) 结构化掩码注意力的模型。显然,该模型具有二次复杂度的版本,也有线性版本,并且二次形式的版本和 SSD 的表达式是同构的!注意力机制中重命名( Q , K , V ) ↦ ( C , B , X ) (Q,K,V)\mapsto (C,B,X) ( Q , K , V ) ↦ ( C , B , X ) Linear \texttt{Linear} Linear L L L
SSM vs. Attention 如下图所示,当SSM的矩阵A A A
矩阵分块算法
Mamba-2 为了利用GPU的 Tensor Core 实现高效的矩阵乘法,首先将半可分离的 SSM 矩阵划分为大小为 Q×Q 的块,然后,利用Semiseparable矩阵的性质来分解每个低秩 的非对角块:
(橙色)每个对角块是一个更小的半可分矩阵,可以以喜欢的方式计算这个乘法,特别是使用 SSD 的二次(类似注意力机制)形式。 (绿色)总共有 T/Q 个不同的绿色块,通过批处理矩阵乘法来计算。 (黄色)注意,黄色项本身是一个 1 - 半可分矩阵,这一步等价于对某些修改后的 A 因子的 SSM 扫描。 (蓝色)与绿色类似,通过批处理矩阵乘法来计算。 Mamba2的架构
与 Mamba-1 相比,Mamba-2 的 SSD层 被视为( A , X , B , C ) ↦ Y (A,X,B,C)\mapsto Y ( A , X , B , C ) ↦ Y A , X , B , C A,X,B,C A , X , B , C B , C B,C B , C X X X
除此之外,作者进行多个预实验得出,当模型规模较大时容易出现不稳定的现象,最后通过在输出投影之前添加一个额外的归一化层 ( 比如 LayerNorm、GroupNorm或 RMSNorm)来缓解这个问题。
值得注意的是,作者表示对于 Mamba 来说,对矩阵进行离散化可能是不必要的,离散化是沿用以前 SSM 的传统,但是以现代视角来看,或许可以直接使用参数化的矩阵即可。当然,在代码中,还是提供了对应的可选项供用户选择。
代码梳理 代码截取时间:2024年9月18日14:40:51
Github 中有三种 mamba 的实现。官方实现 中目录层级较多,并且利用 C 语言 实现了各种优化和加速。此外,有第三方实现 直接在Pytorch上进行优化加速,特别是对并行扫描算法的加速。最后是一个极简实现 ,致力用一个文件实现所有的核心算法,速度也是最慢了,适合用作教学。
本节将采用第二个仓库的代码进行适当的梳理和解析。
1 2 3 4 5 6 7 8 9 import mathfrom dataclasses import dataclassfrom typing import Union import torchimport torch.nn as nnimport torch.nn.functional as Ffrom mambapy.pscan import pscan
ModelArgs 类1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @dataclass class MambaConfig : d_model: int n_layers: int dt_rank: Union [int , str ] = 'auto' d_state: int = 16 expand_factor: int = 2 d_conv: int = 4 dt_min: float = 0.001 dt_max: float = 0.1 dt_init: str = "random" dt_scale: float = 1.0 dt_init_floor = 1e-4 rms_norm_eps: float = 1e-5 base_std: float = 0.02 bias: bool = False conv_bias: bool = True inner_layernorms: bool = False mup: bool = False mup_base_width: float = 128 pscan: bool = True use_cuda: bool = False def __post_init__ (self ): self.d_inner = self.expand_factor * self.d_model if self.dt_rank == 'auto' : self.dt_rank = math.ceil(self.d_model / 16 ) if self.mup: self.mup_width_mult = self.d_model / self.mup_base_width
MambaBlock 类1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 class MambaBlock (nn.Module): def __init__ (self, config: MambaConfig ): super ().__init__() self.config = config self.in_proj = nn.Linear(config.d_model, 2 * config.d_inner, bias=config.bias) self.conv1d = nn.Conv1d(in_channels=config.d_inner, out_channels=config.d_inner, kernel_size=config.d_conv, bias=config.conv_bias, groups=config.d_inner, padding=config.d_conv - 1 ) self.x_proj = nn.Linear(config.d_inner, config.dt_rank + 2 * config.d_state, bias=False ) self.dt_proj = nn.Linear(config.dt_rank, config.d_inner, bias=True ) dt_init_std = config.dt_rank**-0.5 * config.dt_scale if config.dt_init == "constant" : nn.init.constant_(self.dt_proj.weight, dt_init_std) elif config.dt_init == "random" : nn.init.uniform_(self.dt_proj.weight, -dt_init_std, dt_init_std) else : raise NotImplementedError dt = torch.exp( torch.rand(config.d_inner) * (math.log(config.dt_max) - math.log(config.dt_min)) + math.log(config.dt_min) ).clamp(min =config.dt_init_floor) inv_dt = dt + torch.log(-torch.expm1(-dt)) with torch.no_grad(): self.dt_proj.bias.copy_(inv_dt) A = torch.arange(1 , config.d_state + 1 , dtype=torch.float32).repeat(config.d_inner, 1 ) self.A_log = nn.Parameter(torch.log(A)) self.A_log._no_weight_decay = True self.D = nn.Parameter(torch.ones(config.d_inner)) self.D._no_weight_decay = True self.out_proj = nn.Linear(config.d_inner, config.d_model, bias=config.bias) if self.config.inner_layernorms: self.dt_layernorm = RMSNorm(self.config.dt_rank, config.rms_norm_eps, config.mup) self.B_layernorm = RMSNorm(self.config.d_state, config.rms_norm_eps, config.mup) self.C_layernorm = RMSNorm(self.config.d_state, config.rms_norm_eps, config.mup) else : self.dt_layernorm = None self.B_layernorm = None self.C_layernorm = None if self.config.use_cuda: try : from mamba_ssm.ops.selective_scan_interface import selective_scan_fn self.selective_scan_cuda = selective_scan_fn except ImportError: print ("Failed to import mamba_ssm. Falling back to mamba.py." ) self.config.use_cuda = False def _apply_layernorms (self, dt, B, C ): if self.dt_layernorm is not None : dt = self.dt_layernorm(dt) if self.B_layernorm is not None : B = self.B_layernorm(B) if self.C_layernorm is not None : C = self.C_layernorm(C) return dt, B, C def forward (self, x ): _, L, _ = x.shape xz = self.in_proj(x) x, z = xz.chunk(2 , dim=-1 ) x = x.transpose(1 , 2 ) x = self.conv1d(x)[:, :, :L] x = x.transpose(1 , 2 ) x = F.silu(x) y = self.ssm(x, z) if self.config.use_cuda: output = self.out_proj(y) return output z = F.silu(z) output = y * z output = self.out_proj(output) return output def ssm (self, x, z ): A = -torch.exp(self.A_log.float ()) D = self.D.float () deltaBC = self.x_proj(x) delta, B, C = torch.split(deltaBC, [self.config.dt_rank, self.config.d_state, self.config.d_state], dim=-1 ) delta, B, C = self._apply_layernorms(delta, B, C) delta = self.dt_proj.weight @ delta.transpose(1 , 2 ) if self.config.use_cuda: x = x.transpose(1 , 2 ) B = B.transpose(1 , 2 ) C = C.transpose(1 , 2 ) z = z.transpose(1 , 2 ) y = self.selective_scan_cuda(x, delta, A, B, C, D, z=z, delta_softplus=True , delta_bias=self.dt_proj.bias.float ()) y = y.transpose(1 , 2 ) else : delta = delta.transpose(1 , 2 ) delta = F.softplus(delta + self.dt_proj.bias) if self.config.pscan: y = self.selective_scan(x, delta, A, B, C, D) else : y = self.selective_scan_seq(x, delta, A, B, C, D) return y def selective_scan (self, x, delta, A, B, C, D ): deltaA = torch.exp(delta.unsqueeze(-1 ) * A) deltaB = delta.unsqueeze(-1 ) * B.unsqueeze(2 ) BX = deltaB * (x.unsqueeze(-1 )) hs = pscan(deltaA, BX) y = (hs @ C.unsqueeze(-1 )).squeeze(3 ) y = y + D * x return y def selective_scan_seq (self, x, delta, A, B, C, D ): _, L, _ = x.shape deltaA = torch.exp(delta.unsqueeze(-1 ) * A) deltaB = delta.unsqueeze(-1 ) * B.unsqueeze(2 ) BX = deltaB * (x.unsqueeze(-1 )) h = torch.zeros(x.size(0 ), self.config.d_inner, self.config.d_state, device=deltaA.device) hs = [] for t in range (0 , L): h = deltaA[:, t] * h + BX[:, t] hs.append(h) hs = torch.stack(hs, dim=1 ) y = (hs @ C.unsqueeze(-1 )).squeeze(3 ) y = y + D * x return y def step (self, x, cache ): h, inputs = cache xz = self.in_proj(x) x, z = xz.chunk(2 , dim=1 ) x_cache = x.unsqueeze(2 ) x = self.conv1d(torch.cat([inputs, x_cache], dim=2 ))[:, :, self.config.d_conv-1 ] x = F.silu(x) y, h = self.ssm_step(x, h) z = F.silu(z) output = y * z output = self.out_proj(output) inputs = torch.cat([inputs[:, :, 1 :], x_cache], dim=2 ) cache = (h, inputs) return output, cache def ssm_step (self, x, h ): A = -torch.exp(self.A_log.float ()) D = self.D.float () deltaBC = self.x_proj(x) delta, B, C = torch.split(deltaBC, [self.config.dt_rank, self.config.d_state, self.config.d_state], dim=-1 ) delta, B, C = self._apply_layernorms(delta, B, C) delta = F.softplus(self.dt_proj(delta)) deltaA = torch.exp(delta.unsqueeze(-1 ) * A) deltaB = delta.unsqueeze(-1 ) * B.unsqueeze(1 ) BX = deltaB * (x.unsqueeze(-1 )) if h is None : h = torch.zeros(x.size(0 ), self.config.d_inner, self.config.d_state, device=deltaA.device) h = deltaA * h + BX y = (h @ C.unsqueeze(-1 )).squeeze(2 ) y = y + D * x return y, h
关于代码中的矩阵 A A A 为什么采用 A_log 的形式进行初始化和参数化?
作者在 Issue #326 torch.log() 之后再 -torch.exp(A_log) 回来,可以保证参数A A A delta = softplus(dt + self.dt_bias) 可以让参数Δ \Delta Δ
关于代码中的矩阵 B B B 为什么在代码中没有遵循论文里通过零阶保持(ZOH)推导的公式?
作者在 Issue #19 Issue #114 B ˉ = ( Δ A ) − 1 ( exp ( Δ A ) − I ) ⋅ Δ B \bar{B}=(\Delta A)^{-1}(\exp(\Delta A)-I)\cdot\Delta B B ˉ = ( Δ A ) − 1 ( exp ( Δ A ) − I ) ⋅ Δ B B ˉ = Δ B \bar{B}=\Delta B B ˉ = Δ B e x − 1 ∼ x e^x-1\sim x e x − 1 ∼ x
ResidualBlock 类A ResidualBlock is composed of a MambaBlock , a normalization , and a residual connection : ResidualBlock(x) = mamba(norm(x)) + xMambaBlock : its input x is (B, L, D) and its outputs y is also (B, L, D).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class ResidualBlock (nn.Module): def __init__ (self, config: MambaConfig ): super ().__init__() self.mixer = MambaBlock(config) self.norm = RMSNorm(config.d_model, config.rms_norm_eps, config.mup) def forward (self, x ): output = self.mixer(self.norm(x)) + x return output def step (self, x, cache ): output, cache = self.mixer.step(self.norm(x), cache) output = output + x return output, cache class RMSNorm (nn.Module): def __init__ (self, d_model: int , eps: float = 1e-5 , use_mup: bool = False ): super ().__init__() self.use_mup = use_mup self.eps = eps if not use_mup: self.weight = nn.Parameter(torch.ones(d_model)) def forward (self, x ): output = x * torch.rsqrt(x.pow (2 ).mean(-1 , keepdim=True ) + self.eps) if not self.use_mup: return output * self.weight else : return output
Mamba 类1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Mamba (nn.Module): def __init__ (self, config: MambaConfig ): super ().__init__() self.config = config self.layers = nn.ModuleList([ResidualBlock(config) for _ in range (config.n_layers)]) def forward (self, x ): for layer in self.layers: x = layer(x) return x def step (self, x, caches ): for i, layer in enumerate (self.layers): x, caches[i] = layer.step(x, caches[i]) return x, caches
Mamba 第二代同样有第三方实现,其中第二个“直接实现”截止写下这篇博客时还未完善,这里我们采用第三个仓库的版本进行整理。
该版本代码以语言模型(language model, lm)为背景而编写,所以有些许针对性的代码。另外,为简洁,下面的梳理注释中仅保留与 Mamba 第一代有区别的地方。
1 2 3 4 5 6 7 8 9 10 import jsonfrom dataclasses import dataclassfrom typing import Iterable, NamedTuple, TypeAlias, castimport torchimport torch.nn.functional as Ffrom einops import rearrange, repeatfrom torch import LongTensor, Tensor, nnDevice: TypeAlias = str | torch.device | None
ModelArgs 类1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @dataclass class Mamba2Config : d_model: int n_layer: int = 24 d_state: int = 128 d_conv: int = 4 expand: int = 2 headdim: int = 64 chunk_size: int = 64 vocab_size: int = 50277 pad_vocab_size_multiple: int = 16 def __post_init__ (self ): self.d_inner = self.expand * self.d_model assert self.d_inner % self.headdim == 0 self.nheads = self.d_inner // self.headdim if self.vocab_size % self.pad_vocab_size_multiple != 0 : self.vocab_size += ( self.pad_vocab_size_multiple - self.vocab_size % self.pad_vocab_size_multiple )
Mamba2 类1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 class Mamba2 (nn.Module): def __init__ (self, args: Mamba2Config, device: Device = None ): super ().__init__() self.args = args self.device = device d_in_proj = 2 * args.d_inner + 2 * args.d_state + args.nheads self.in_proj = nn.Linear(args.d_model, d_in_proj, bias=False , device=device) conv_dim = args.d_inner + 2 * args.d_state self.conv1d = nn.Conv1d( in_channels=conv_dim, out_channels=conv_dim, kernel_size=args.d_conv, groups=conv_dim, padding=args.d_conv - 1 , device=device, ) self.dt_bias = nn.Parameter(torch.empty(args.nheads, device=device)) self.A_log = nn.Parameter(torch.empty(args.nheads, device=device)) self.D = nn.Parameter(torch.empty(args.nheads, device=device)) self.norm = RMSNorm(args.d_inner, device=device) self.out_proj = nn.Linear(args.d_inner, args.d_model, bias=False , device=device) def forward (self, u: Tensor, h: InferenceCache | None = None ): """ Arguments u: (batch, seqlen, d_model) input. seqlen should be a multiple of chunk_size. h: hidden states for inference step. Initialized to 0s if not present. Return (y, h) y: (batch, seqlen, d_model) output h: updated inference cache after processing `u` """ if h: return self.step(u, h) A = -torch.exp(self.A_log) zxbcdt = self.in_proj(u) z, xBC, dt = torch.split( zxbcdt, [ self.args.d_inner, self.args.d_inner + 2 * self.args.d_state, self.args.nheads, ], dim=-1 , ) dt = F.softplus(dt + self.dt_bias) conv_state = F.pad( rearrange(xBC, "b l d -> b d l" ), (self.args.d_conv - u.shape[1 ], 0 ) ) xBC = silu( self.conv1d(xBC.transpose(1 , 2 )).transpose(1 , 2 )[:, : u.shape[1 ], :] ) x, B, C = torch.split( xBC, [self.args.d_inner, self.args.d_state, self.args.d_state], dim=-1 ) x = rearrange(x, "b l (h p) -> b l h p" , p=self.args.headdim) y, ssm_state = ssd( x * dt.unsqueeze(-1 ), A * dt, rearrange(B, "b l n -> b l 1 n" ), rearrange(C, "b l n -> b l 1 n" ), self.args.chunk_size, device=self.device, ) y = y + x * self.D.unsqueeze(-1 ) y = rearrange(y, "b l h p -> b l (h p)" ) y = self.norm(y, z) y = self.out_proj(y) h = InferenceCache(conv_state, ssm_state) return y, h def step (self, u: Tensor, h: InferenceCache ) -> tuple [Tensor, InferenceCache]: """Take a single inference step for the current input and hidden state Arguments u: (batch, 1, d_model) h: initial/running hidden state Return (y, h) y: (batch, 1, d_model) h: updated hidden state """ assert u.shape[1 ] == 1 , "Only one token can be decoded per inference step" zxbcdt = self.in_proj(u.squeeze(1 )) z, xBC, dt = torch.split( zxbcdt, [ self.args.d_inner, self.args.d_inner + 2 * self.args.d_state, self.args.nheads, ], dim=-1 , ) h.conv_state.copy_(torch.roll(h.conv_state, shifts=-1 , dims=-1 )) h.conv_state[:, :, -1 ] = xBC xBC = torch.sum ( h.conv_state * rearrange(self.conv1d.weight, "d 1 w -> d w" ), dim=-1 ) xBC += self.conv1d.bias xBC = silu(xBC) x, B, C = torch.split( xBC, [self.args.d_inner, self.args.d_state, self.args.d_state], dim=-1 ) A = -torch.exp(self.A_log) dt = F.softplus(dt + self.dt_bias) dA = torch.exp(dt * A) x = rearrange(x, "b (h p) -> b h p" , p=self.args.headdim) dBx = torch.einsum("bh, bn, bhp -> bhpn" , dt, B, x) h.ssm_state.copy_(h.ssm_state * rearrange(dA, "b h -> b h 1 1" ) + dBx) y = torch.einsum("bhpn, bn -> bhp" , h.ssm_state, C) y = y + rearrange(self.D, "h -> h 1" ) * x y = rearrange(y, "b h p -> b (h p)" ) y = self.norm(y, z) y = self.out_proj(y) return y.unsqueeze(1 ), h
Mamba2LMHeadModel 类1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 class Mamba2LMHeadModel (nn.Module): def __init__ (self, args: Mamba2Config, device: Device = None ): super ().__init__() self.args = args self.device = device self.backbone = nn.ModuleDict( dict ( embedding=nn.Embedding(args.vocab_size, args.d_model, device=device), layers=nn.ModuleList( [ nn.ModuleDict( dict ( mixer=Mamba2(args, device=device), norm=RMSNorm(args.d_model, device=device), ) ) for _ in range (args.n_layer) ] ), norm_f=RMSNorm(args.d_model, device=device), ) ) self.lm_head = nn.Linear( args.d_model, args.vocab_size, bias=False , device=device ) self.lm_head.weight = self.backbone.embedding.weight @staticmethod def from_pretrained (huggingface_model_id: str , device: Device = None ): from transformers.utils import CONFIG_NAME, WEIGHTS_NAME from transformers.utils.hub import cached_file config_path = cached_file(huggingface_model_id, CONFIG_NAME) assert config_path, "Failed to get huggingface config file" state_dict_path = cached_file(huggingface_model_id, WEIGHTS_NAME) assert state_dict_path, "Failed to get huggingface state dict file" config = json.load(open (config_path)) args = Mamba2Config( d_model=config["d_model" ], n_layer=config["n_layer" ], vocab_size=config["vocab_size" ], pad_vocab_size_multiple=config["pad_vocab_size_multiple" ], ) map_location = "cpu" if device is None else device state_dict = torch.load( state_dict_path, weights_only=True , map_location=map_location, mmap=True ) model = Mamba2LMHeadModel(args, device=device) model.load_state_dict(state_dict) model.eval () return model def forward ( self, input_ids: LongTensor, h: list [InferenceCache] | list [None ] | None = None ) -> tuple [LongTensor, list [InferenceCache]]: """ Arguments input_ids: (batch, seqlen) tokens from `EleutherAI/gpt-neox-20b` tokenizer h: hidden states for inference step. If present the constant-time (wrt sequence length) inference path will be taken, input_ids should have shape (batch, 1) containing the next batch of prompt token. Return (logits, h) logits: (batch, seqlen, vocab_size) h: updated inference cache after processing `input_ids` """ seqlen = input_ids.shape[1 ] if h is None : h = [None for _ in range (self.args.n_layer)] x = self.backbone.embedding(input_ids) for i, layer in enumerate (self.backbone.layers): y, h[i] = layer.mixer(layer.norm(x), h[i]) x = y + x x = self.backbone.norm_f(x) logits = self.lm_head(x) return logits[:, :seqlen], cast(list [InferenceCache], h) def generate ( self, input_ids: LongTensor, max_new_length: int = 20 , temperature: float = 1.0 , top_k: int = 50 , top_p: float = 1.0 , eos_token_id: int = 0 , ) -> Iterable[tuple [int , list [InferenceCache]]]: prefix, tokens = input_ids[:-1 ], input_ids[-1 :].unsqueeze(0 ) n_chunked = (prefix.shape[0 ] // self.args.chunk_size) * self.args.chunk_size if n_chunked > 0 : _, h = self(prefix[:n_chunked].unsqueeze(0 ), None ) else : h = [ InferenceCache.alloc(1 , self.args, device=self.device) for _ in range (self.args.n_layer) ] for i in range (n_chunked, prefix.shape[0 ]): _, h = self(prefix[i : i + 1 ].unsqueeze(0 ), h) for _ in range (max_new_length): with torch.no_grad(): out, h = self(tokens, h) logits = out[0 , -1 ] if temperature != 1.0 : logits = logits / temperature if top_k > 0 : indices_to_remove = logits < torch.topk(logits, k=top_k)[0 ][-1 ] logits[indices_to_remove] = -torch.inf if top_p < 1.0 : sorted_logits, sorted_indices = torch.sort(logits, descending=True ) cum_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1 ), dim=-1 ) sorted_indices_to_remove = cum_probs > 0.5 sorted_indices_to_remove[1 :] = sorted_indices_to_remove[:-1 ].clone() sorted_indices_to_remove[0 ] = False indices_to_remove = sorted_indices[sorted_indices_to_remove] logits[indices_to_remove] = -torch.inf probs = F.softmax(logits, dim=-1 ) next_token = torch.multinomial(probs, num_samples=1 ) if next_token.item() == eos_token_id: return tokens = next_token.unsqueeze(0 ) yield cast(int , next_token.item()), h
ssd() 函数1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 def ssd (x, A, B, C, chunk_size, initial_states=None , device: Device = None ): """Structed State Space Duality (SSD) - the core of Mamba-2 This is almost the exact same minimal SSD code from the blog post. Arguments x: (batch, seqlen, n_heads, d_head) A: (batch, seqlen, n_heads) B: (batch, seqlen, n_heads, d_state) C: (batch, seqlen, n_heads, d_state) Return y: (batch, seqlen, n_heads, d_head) """ assert x.shape[1 ] % chunk_size == 0 x, A, B, C = [ rearrange(m, "b (c l) ... -> b c l ..." , l=chunk_size) for m in (x, A, B, C) ] A = rearrange(A, "b c l h -> b h c l" ) A_cumsum = torch.cumsum(A, dim=-1 ) L = torch.exp(segsum(A, device=device)) Y_diag = torch.einsum("bclhn, bcshn, bhcls, bcshp -> bclhp" , C, B, L, x) decay_states = torch.exp(A_cumsum[:, :, :, -1 :] - A_cumsum) states = torch.einsum("bclhn, bhcl, bclhp -> bchpn" , B, decay_states, x) if initial_states is None : initial_states = torch.zeros_like(states[:, :1 ]) states = torch.cat([initial_states, states], dim=1 ) decay_chunk = torch.exp(segsum(F.pad(A_cumsum[:, :, :, -1 ], (1 , 0 )), device=device)) new_states = torch.einsum("bhzc, bchpn -> bzhpn" , decay_chunk, states) states, final_state = new_states[:, :-1 ], new_states[:, -1 ] state_decay_out = torch.exp(A_cumsum) Y_off = torch.einsum("bclhn, bchpn, bhcl -> bclhp" , C, states, state_decay_out) Y = rearrange(Y_diag + Y_off, "b c l h p -> b (c l) h p" ) return Y, final_state
参考 A Visual Guide to Mamba and State Space Models - Maarten Grootendorst 一文通透想颠覆Transformer的Mamba:从SSM、HiPPO、S4到Mamba_mamba模型-CSDN博客 通透理解FlashAttention与FlashAttention2:全面降低显存读写、加快计算速度-CSDN博客 State Space Duality (Mamba-2) Part III - The Algorithm | Tri Dao 一文通透mamba2「力证Transformer are SSM」:从SSM、半可分矩阵、SMA、SSD到mamba2-CSDN博客