对比学习的发展、应用与技巧
自监督学习
自监督学习(Self-supervised Learning)是一种利用输入数据本身提供的某种形式的“监督信号”来生成训练标签,而不需要人工标注的真实标签的机器学习方法。
在自监督学习中,模型通过设计一些能够从原始数据中提取信息的任务(通常被称为预训练任务/代理任务 Pretext Tasks),如重构缺失部分、预测上下文关系、进行实例或特征间的对比等,来自动产生训练目标。通过解决这些任务,模型就可以学习到数据的内在结构和表示(或表征 representation),并以此为基础进一步用于下游的有监督学习任务(Downstream Tasks)。
事实上,这类学习数据的“表示”的机器学习方法也被称为表示学习/表征学习。
与无监督学习相比,自监督学习虽然也是在没有标签的情况下进行训练,但它不是简单地寻找数据中的自然聚类或其他统计特性。因此,可以说自监督学习是无监督学习的一种延伸或增强形式,它在实践中通常能够更有效地利用大量未标注数据,并且对于许多复杂任务已经展示出了显著的优势。
生成式与对比式
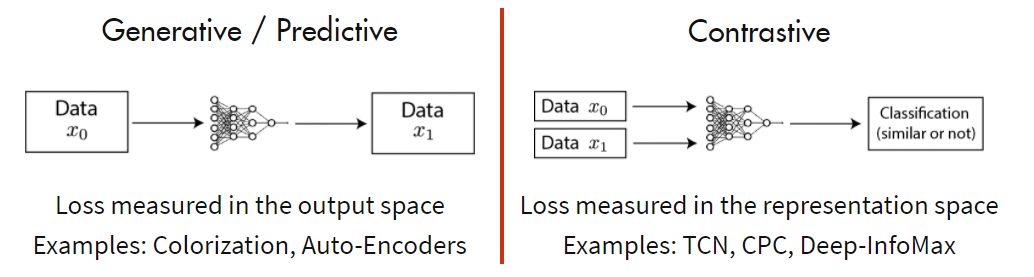
自监督学习的方法有很多,如今比较常见的方法通过预训练任务的设计可以做如下分类:
一、生成式预训练任务
- 重构任务:从部分输入重建完整输入,例如图像补全、像素级预测(如图像色彩化)等。
- 此类任务通常以自动编码器架构为主,详见 Introduction to AutoEncoders;
- 序列预测:在NLP中,还可能训练模型去预测一个句子中的下一个单词,或者预测句子顺序等。
- 相关的经典模型 BERT 详见:
- 结合 ViT 并借鉴 BERT 的 BEiT与MAE 详见:
二、对比学习:通过构建正负样本对,在特征空间中拉近同一实例的不同视图间的距离,同时推远不同实例之间的距离。(如:SimCLR、MoCo系列)
三、其他
- 排列恢复:视觉领域中,像Jigsaw Puzzle Solver这样的任务要求模型恢复打乱的图像块顺序,从而学习空间结构信息。
- 多模态学习:研究者还探索了跨模态的自监督学习,如将文本描述与对应图片匹配(如CLIP),或者音频与视频同步片段的配对。
- 因果推理和时间序列预测:对于时序数据,可以设计任务预测未来状态(如视频帧预测)或逆向模拟以恢复过去的状态。
线性探测
线性探测(Linear Protocol / Linear Probing / Linear Evaluation)一般是指将 自监督学习/表示学习 学习到的 representation 通过 线性层(MLP 层、Softmax层 等)运用到 有监督的下游任务 时的微调(fine-tune)过程。注意,该微调过程不再更新前面的网络参数,即前置网络被“冻住”(freeze),只学习线性层的参数。
通过线性探测可以一定程度上衡量一个自监督学习模型的优劣。
对比学习范式
对比学习(Contrastive Learning)关注于学习样本之间的相似性和差异性。
对比学习模型提出了将数据区分正负样本的思想,通过比较和区分正样本对 Positive sample(通常是同一对象的不同视图或表示形式,如同一张图片的旋转、裁剪版本或者同一句子的不同表达方式)与负样本对 Negative sample(来自不同对象的视图或表示)来优化学习过程。这也是对比学习中“对比”二字的由来。
首个工作 InstDisc:Unsupervised Feature Learning via Non-Parametric Instance Discrimination
代理任务
具体来说,在对比学习任务中,模型的目标是学习一个或多个 编码器 将输入数据映射到一个特征空间中,使得同一实例的不同变体在该空间中的距离尽可能接近(即对比损失最小),而不同实例的变体在特征空间中的距离尽可能远。通常认为这样学到的表征具有较强的鲁棒性和判别力。
对比学习的代理任务是十分灵活的,编码器的设计可以灵活选择,正负样本的概念也并不死板。
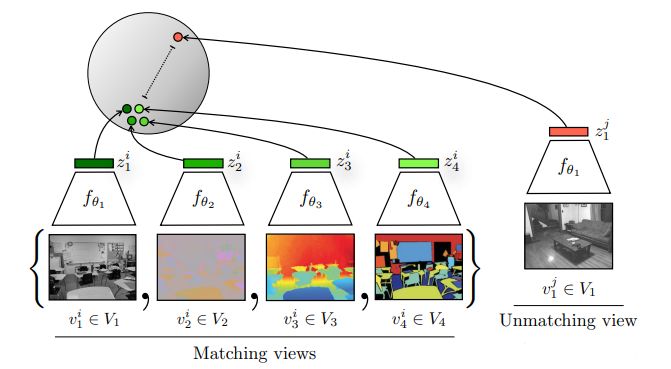
如上图所示,该论文将一张图片的四种view数据增强结果(包含其原始的图像,对应的深度信息,SwAV ace normal,语义分割)视为 Matching 的正样本,所有其他图片/view 视为负样本。(From paper:Contrastive Multiview Coding, CMC)
虽然这些不同的view来自不同的传感器,或者不同的模态,但是这些所有的输入其实对应的都是一整的图片,一个东西,那么它们就应该互为正样本,相互配对。而这些相互配对的视角在特征空间中应该尽可能的相近,而与其他的视角尽可能的远离。
特别地,将特定的图像和文本视为匹配的正样本对时,这就视为是一种多模态的表示学习了。Google 的 CLIP 模型正是如此。
损失函数
将代理任务进行形式化表达,如下图所示。我们在一个 的 个数据中,将第 个输入 进行数据增强(augment)得到 然后通过编码器得到一对正样本对。
我们称上方的样本/特征 为锚点(anchor),下方的样本 为上下文嵌入(Context Embedding)。然后剩下的所有数据也都通过下面的编码器进行编码得到负样本(保证负样本之间属于同一个特征空间),所有的负样本与 一起组成一个样本的集合。
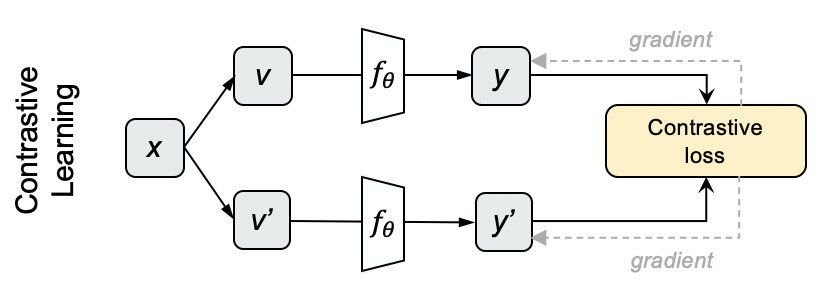
于是,整个学习的程就是最小化一个设计好的目标函数 Contrastive Loss,学习参数使模型能从样本集合里找到与锚点最相似的样本。
InfoNCE
待更
InfoNCE Loss 是对 NCE Loss 的一种的一般形式可以表示为:
其中:
- 是一个锚点样本。
- 是与锚点样本相关的正样本,它们通常来自于同一个实例的不同视图或变体。
- 是与锚点样本不相关的负样本,它们来自其他不同的实例。
- 是负样本的数量。
- 是一个相似度函数,它可以是一个内积、 cosine相似度或者其他任何能衡量两个样本在特征空间中距离的函数。
该公式的目标是最大化锚点样本和正样本之间的相似度得分,同时最小化锚点样本与其他负样本之间的相似度得分。通过优化这个损失函数,模型学习到一个能够将同一实例的不同表示拉近,并将不同实例的表示推开的嵌入空间。
温度系数
学习率 30 (?)
一致性与庞大性
在上一章中我们提到了对比学习的基本思想,其中最主要的一点就是通过划分正负样本来进行对比式的任务学习。但实际上,负样本的数量往往很庞大,这在一方面为模型训练提供了更丰富的学习空间,但在另一方面对计算机的内存要求提出了挑战。
在如何“利用有限存储空间存储大量的负样本”的工作中,早期的不同论文提出了各种方法,最终大家都几乎同一使用了 MoCo (Momentum Contrast)中使用的 动量编码器对比策略。该方法较好地解决了 MoCo 论文 中提出的有限内存下样本集合的一致性和庞大性问题。
Paper:Momentum Contrast for Unsupervised Visual Representation Learning
Github: https://github.com/facebookresearch/moco
对比学习=字典查询
为了更好地将 MoCo 以前的对比学习方法进行统一起来,并强调一致性和庞大性的问题。MoCo 论文中把对比学习归纳为一个词典查询问题:
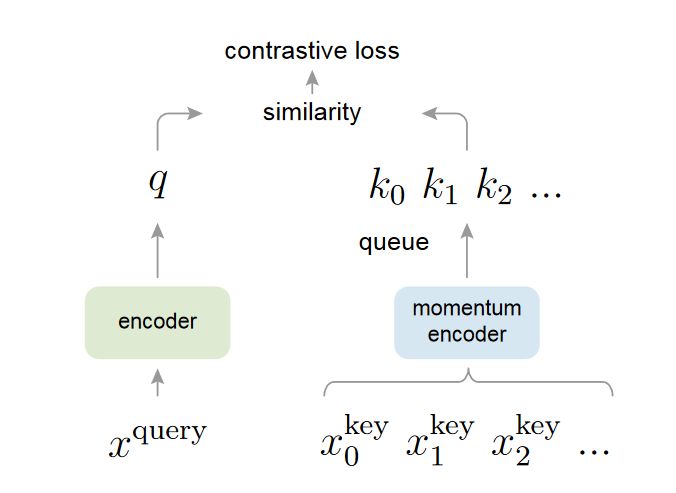
将正负样本都通过编码器 所得的输出看成是一个特征 key,将正样本通过另外一个编码器 所得到的输出看成是一个 query。对比学习本质上就是希望在字典中找到与 query 最匹配的那个 key,而这个 key 是就对应着正样本,它通过一系列的数据增强变化获得,所以语义信息应该相同,在特征空间上也应该类似,而与其他的负样本的特征 key应该尽可能的远离。
Large 庞大性
在有限内存内,让字典尽可能更大就可以从连续高维空间做更多的采样。字典内 key 越多,表示的信息越丰富,匹配时更容易找到具有区分性的本质特征。 相反,如果字典过小,模型可能学到 shortcut 捷径,不能泛化。
Consistent 一致性
字典里的 key 应该由相同的或相似的编码器生成。否则用 query 做字典查询时,很有可能 找到和 query 使用相似编码器生成的 key,而不是语义相似的 key,这是另一种形式的 shortcut solution 捷径解。
端到端学习 | SimCLR
SimCLR,准确来说是 SimCLR v1 是 MoCo 之前一种典型的 end-to-end 端到端学习的对比学习方法(From paper:A Simple Framework for Contrastive Learning of Visual Representations)。
如下图 (a) 所示,该方法的负样本就来自于一个 内部,而不引入batch 外的其他负样本。方向传播更新参数时,也是连同 query 和 key 两边的编码器一起更新,所以在一个 batch 内的 key 都是满足一致性的。
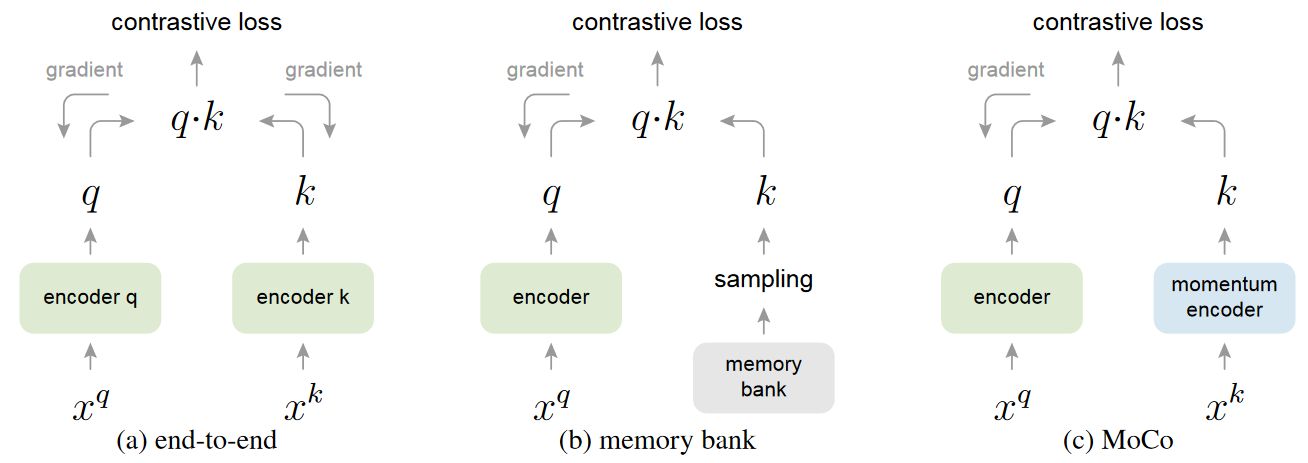
由于 SimCLR 来自于 Google,论文中也提到他们所使用的 batch_size 很大(8192),这才得以弥补“一个batch中能生成的负样本数量太小”的问题。因此,SimCLR 的成功很难被普通显卡复现——对于普通显卡丧失了庞大性。
不过,SimCLR 还给出了额外的可提升准确率百分点的Trick,这将在下一章介绍。
存储容器 | InstDisc
对比学习的起始代表论文 InstDisc 解决内存不足的方法则是提出了 memory bank 的结构。
InstDisc 只采用一个可学习的编码器,初始化编码器后将所有数据都通过编码器生成得到 key 然后存储在 memory bank 内。因为编码后每个 key 得到了较大程度的降维,所以都存在 memory bank 内也不会占用太大的空间。
如上图(b)所示,InstDisc 每次前向过程都从中随机抽取4096个负样本 key 进行对比学习,反向传播更新编码器参数后,将抽出来的这些 key 所对应的原数据经过新更新的编码器重新编码后覆盖原来 memory bank 里的 key。
该方法一定程度上解决了内存大小不足的问题,但是 memory bank 内的 key 因为可能来自不同时刻的编码器(不同参数),所以它们的特征空间可能是不一致的。
动量编码器 | MoCo
MoCo 提出将字典用队列(queue)这样的数据结构进行存储,队列里面的元素就是一系列的特征 key,如下图©所示。
在模型训练的过程中,每一个 就会有新的一批 key 进入队列,当数量超过队列长度时,也会有一批老的 key 移出队列。这样一来就可以将字典的大小(队列长度)与 的大小解耦——区别于InstDisc方法。这样就可以在训练时使用比较标准的 batch_size(如),而且队列长度还可以作为一个超参数进行控制。
此外,删除一批老的 key 可能是有益的,因为这些 key 是最过时的,与最新的 key 最不一致。
然而,更新队列中的 key 的编码器 和 InstDisc方法 一样没法通过梯度回传来更新参数。实际上,InstDisc 方法等价于用生成 query 的编码器 的参数 作为生成 key 的编码器 的参数。之前我们也提到这会导致一致性被破坏。
于是,MoCo 就提出了动量更新 的方式:
其中, 是动量参数。
通过动量更新的方式,虽然特征key还是由不同时刻的编码器得到的,但是这些不同时刻的编码器的区别比较小,所以其一致性还是比较强的。
MoCo 的实验还说明,当 时效果较好,所以一个变化缓慢的编码器对对比学习是有好处的,因为保留了特征一致性。
1 | # Algorithm 1 Pseudocode of MoCo in a PyTorch-like style |
关于 MoCo 的详细源码解析详见:源码解析MoCo:动量法+对比学习
聚类中心法 | SwAV
SwAV(Swap Assignment Views)另辟蹊径,为了避免对大量负样本做比较,SwAV提出将对比学习和聚类方法结合起来,希望相似的样本都聚集在一个聚类中心附近,不相似的样本推到别的聚类中心。这样做也不是偶然,因为聚类也是无监督特征表示学习的方法。
此外,SwAV设置的代理任务也有所不同,它认为来自同一张图片的特征应该能够相互预测对方,所以相应的损失函数不再是 InfoNCE 而是 MSE。
Paper:Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
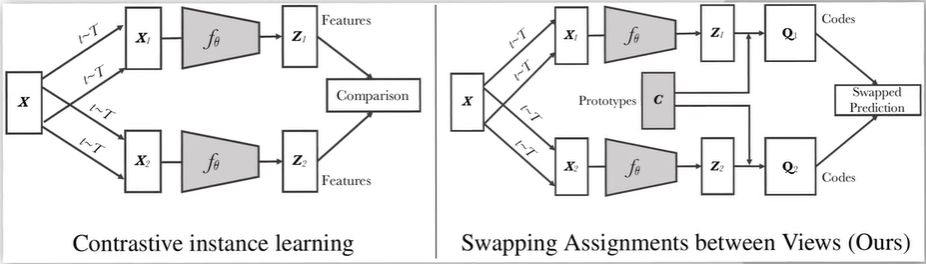
如上图所示, 为聚类中心 Prototypes,是一个 的矩阵,其中 是特征 的维度, 是聚类中心的个数(如)。正样本对的特征 应该靠近同一个中心,即 应该尽可能与 接近。
实际上这是 SwAV 论文的作者通过将自己之前对聚类学习、元学习的方法运用于对比学习的成果,关于 Prototype 的相关知识详见:
待更
SwAV的性能优势不仅仅是与聚类的方法融合了在一起,其还有另外的一个性能提升点Multi-crop ,这将在下一章介绍。
Trick提升
百花齐放的对比学习论文中,不少提升学习能力的 Trick 得到了大家的认可。本章将介绍在这些论文中那些可圈可点的技巧,以及各位大佬们相互借鉴之后得到的成果。
More MLP
第一个技巧是在训练时新增一层 MLP 层,这会促使模型学习到更有用的特征。主要贡献来自于 SimCLR(v1) 。
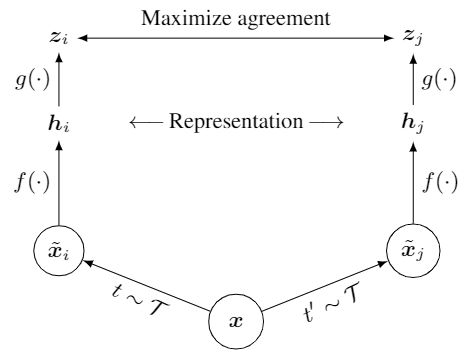
上图为 SimCLR v1 的结构图,对于给定输入 ,SimCLR首先研究了大量可以对图像进行数据增强(随机裁剪、颜色失真、高斯模糊等)的方法来生成正负样本对,然后采用 ResNet50 作为 encoder,即函数 。在编码得到表示 后,SimCLR 并没有像以往的工作一样直接将 进行 Loss,而是再通过 MLP / project function 将 映射为更低维的 ,然后再将 用于目标函数计算。
需要注意的是, MLP 仅仅在训练的时候才使用,在测试的时候是不使用的。测试时仅使用编码器 得到的 到下游任务中 。虽然没有理论支持,但是加上 MLP 切实可行地让模型训练的结果更好了!
此后 MoCo 借鉴了 SimCLR 的这个 project function 后,发布了 MoCo v2;后来的 SimCLR v2 则将MLP的层数提高,测试得设置为 2 层时效果为优,并且 SimCLR v2 加大了 backbone 网络为ResNet-152并且使用了selective kernels(也就是SE网络)。
Multi Crop
SwAV 在论文中还使用了名为 Multi Crop 的 Trick 帮助提升其能力。该方法起源于作者希望关注到图片更多的正样本信息。
以往的对比学习方法都是在一张 的图片上用两个 的 crop 求两个正样本,但是因为 crop 过大,所以选取的这些 crop 都是基于全局特征的,可能忽视了局部特征。
multi-crop 的思路就是选择两个 的 crop 去注意全局特征,选择四个 的 crop 去注意局部特征。这样在计算量变化不大的情况下,可以获取更多的正样本,也可以同时注意了全局特征与局部的特征。
再见负样本
模型坍塌问题
BYOL
隐式负样本对比
Simsiam
其他细节
BN的信息泄露
数据增强方法
附:从 NCE 到 InfoNCE
NCE Loss
Noise-Contrastive Estimation (NCE) 损失 通常用于估计概率模型的参数,尤其是未归一化模型。
NCE的背景任务是用一个参数化的分布去估计一个真实的分布,一般写成Gibbs distribution的形式
为配分函数,这种形式保证了且对x积分和为1,一般使用目标函数,然后用最大似然估计去求解,
因为我们不知道真实分布,所以一般是采用采样N个样本去估计它
但是配分函数的求解是个问题,不管x是连续的还是离散的,我们都难以对所有的x进行积分或者求和,但我们可以把它变成一个可以训练的参数Z,然后让神经网络去找一个最优的参数,因此最大似然的目标就变成了
上式明显有一个平凡解,就是让,于是就接近无限大了,但这并不我们想要的结果,NCE就是要解决这个问题,它通过求解一个二分类任务,可以得到原本的目标函数的解的近似
在对比学习背景下,NCE Loss 可以表示为一个二分类问题的形式,其中目标是区分真实数据样本和噪声样本:
假设 是数据的真实分布, 是噪声分布,而 是需要估计的参数,对于某个观测样本,其来自真实分布的概率为。NCE的目标是在一系列样本中区分出真实的观测样本和其他从噪声分布采样的样本。数学公式可以写作:
其中, 是正负样本的比例系数,即每个真实样本与 ( K ) 个噪声样本进行比较。
在实际应用中,比如对比学习中,我们不直接用这个原始的NCE损失形式来计算两个向量之间的相似度,而是采用一种变体,如InfoNCE,它更适用于大规模对比学习任务。InfoNCE将每个样本与其他样本(包括正样本和多个负样本)的相似度比较转化为一个可优化的损失函数。但严格来说,InfoNCE是对NCE思想的一个扩展应用,尤其是在深度学习表征学习领域。
待更:[译] Noise Contrastive Estimation - 知乎 (zhihu.com)
Noise Contrastive Estimation - Lei Mao’s Log Book
对比学习损失(InfoNCE loss)与交叉熵损失的联系,以及温度系数的作用 - 知乎 (zhihu.com)