注意力机制范式
生物学注意力
灵长类动物的视觉系统接受了大量的感官输入, 这些感官输入远远超过了大脑能够完全处理的程度。 然而,并非所有刺激的影响都是相等的。
意识的聚集和专注使灵长类动物能够在复杂的视觉环境中将注意力引向感兴趣的物体,例如猎物和天敌。 只关注一小部分信息的能力对进化更加有意义,使人类得以生存和成功。
深度学习中的 注意力机制(Attention Mechanism) 就是一种模仿人类视觉和认知系统的方法,它允许神经网络在处理输入数据时集中注意力于相关的部分。通过引入注意力机制,神经网络能够自动地学习并选择性地关注输入中的重要信息,提高模型的性能和泛化能力。
自主性提示
“美国心理学之父”,威廉·詹姆斯,对人类的这种注意力机制提出了双组件框架:受试者基于 非自主性提示 和 自主性提示 有选择地引导注意力的焦点。
- 非自主性提示:万花丛中一点红——我们更容易关注到花园中与其他白花有明显不同的红花。
- 自主性提示:受到了认知和意识的控制,自主关注某个东西。如看球赛时我们有意识地关注正在踢球的球员。
那么如何通过这两种提示, 用神经网络来设计注意力机制的框架呢?
考虑一个简单情况: 只使用“非自主性提示”。 此时可以简单地使用参数化的全连接层, 甚至是非参数化的最大池化层或平均池化层,这样就能把数据通过“非自主提示的注意力”得到输出——没有自主性。
接下来我们引入“自主性提示”,将注意力机制与池化层区分开来。
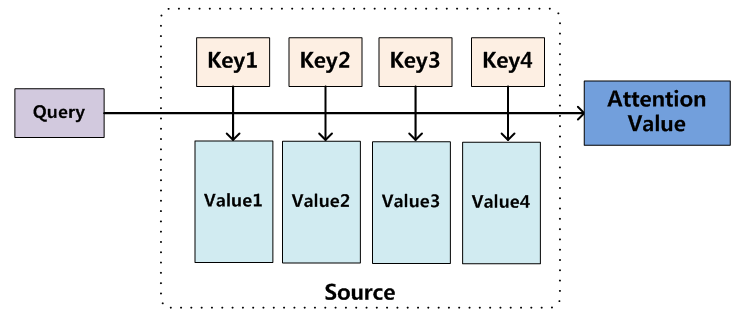
如上图所示,我们把输入数据(keys)和通过“非自主性提示”(如池化层)得到的对应的数据(values)用键值对的方式进行描述,它们统称为 Source。而“自主性提示”就是一个想要自主查询的目标(query)。于是如何设定规则让系统选择出最需要注意到的 key —— 最接近 query 的 key,这就是注意力机制的核心。
机制的本质
统计学习/机器学习领域中有这样一种处理回归问题的方法,被称作 Nadaraya-Watson核回归。它引入核函数的思想实现了非参数统计,它利用样本距离的占比作为权重,然后对样本输出进行加权平均,进而得到整个样本的拟合函数:
f(x)=i=1∑n∑j=1nK(x−xj)K(x−xi)yi,
式中,K(⋅) 为核函数。
受此启发,注意力机制的输出也规定是由 values 的加权平均值给出的,权重由某种相似性度量函数Similarity(⋅) 给出。从而我们有:
Attention(Query,Source)=i=1∑nSimilarity(Query,Keyi)⋅Valuei
更进一步地,参考Nadaraya-Watson核回归的设计思路,如果我们将核函数取为高斯函数,就有:
f(x)=i=1∑n∑j=1nexp(−21(x−xj)2)exp(−21(x−xi)2)yi=i=1∑nsoftmax(−21(x−xi)2)yi
我们将上式中softmax 函数的自变量称为注意力评分函数(attention scoring function),简称评分函数(scoring function),记为a(⋅)。
则上述过程可以看作对Keys 和Query 计算评分函数,然后将结果a 通过softmax 函数进行归一化。因为softmax 归一化使得函数值在0到1之间,所以这就相当于得到每一个Value 的注意力权重(概率分布)。从而其加权平均(期望)就是我们需要的输出。
整个过程如下图所示:
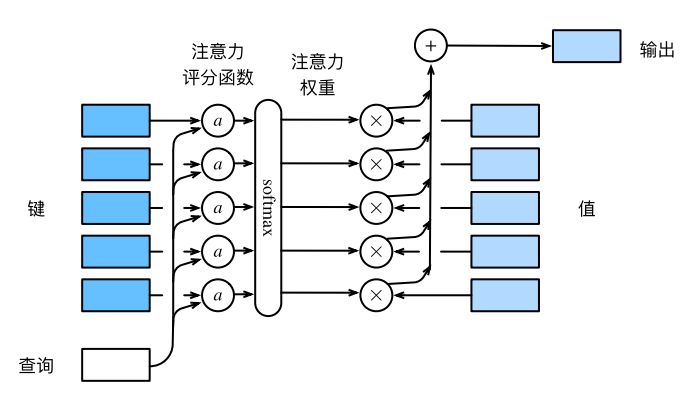
最终,当我们设计不同的注意力机制时,其实我们可以只需要设计不同的评分函数。不难发现,Nadaraya-Watson核回归中的评分函数是由L2 范数/欧氏距离给出的。我们同样也可以设计余弦距离或其他相似性。
注意力评分函数
在上一节中,我们已经指出注意力机制的本质,其中我们可以灵活的改变评分函数来应对不同的问题。下面我们将总结出一些常见情况/输入数据下评分函数的选取。
加性注意力
当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。
a(q,k)=wv⊤tanh(Wqq+Wkk)∈R
该过程可以看作是将查询q 与输入键k 连结之后,通过带有权重参数的多层感知机(禁用偏置项),然后利用tanh 作为激活函数得出。
缩放点积注意力
使用点积可以得到计算效率更高的评分函数, 但是点积操作要求查询和键具有相同的长度d 。
假设查询和键的所有元素都是独立的随机变量, 并且都满足零均值和单位方差, 那么两个向量的点积的均值为0,方差为d。 为确保无论向量长度如何,点积的方差在不考虑向量长度的情况下仍然是1, 我们再将点积除以d, 则 缩放点积注意力(scaled dot-product attention)评分函数为:
a(q,k)=q⊤k/d
考虑小批量计算时,整个注意力机制的输出可以写成:
softmax(dQK⊤)V
向量点积之所以能表示相似度,是因为其源头是余弦距离(不考虑方向)
多头注意力机制
在实践中,为了捕捉不同方面的信息,将注意力机制分为多个头,形成多个子空间表示(representation subspaces)是有意义的。
用独立学习得到的h 组不同的 线性投影(linear projections)来变换查询、键和值。 然后将它们并行地送到注意力池化中。 最后,将这h 个输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 这种设计就被称为 多头注意力(Multi-Head Attention)。
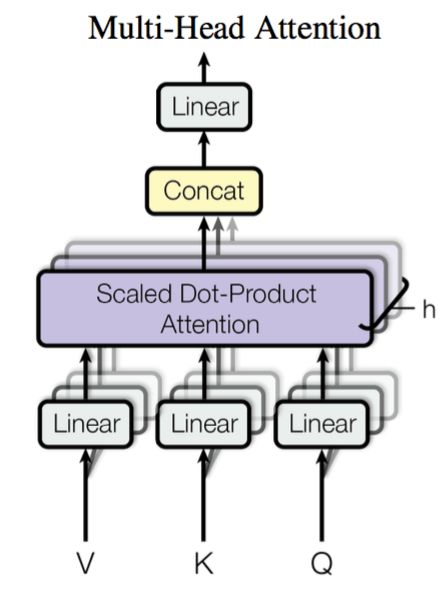
第i 个 head 的查询、键和值线性变换后的结果如下:
以小批量样本输入的矩阵形式给出,此处暂且忽略板书时对符号的加粗
Qi=QWiQ,Ki=KWiK,Vi=VWiV
从而第i 个 head 的输出为:
headiAttention(Qi,Ki,Vi)=Attention(Qi,Ki,Vi)=softmax(dQiKi⊤)Vi
最终的多头注意力输出为:
Attention(Q,K,V)=Concat(head1,..,headi,..)WO
自注意力机制
自注意力机制(self-attention)也被称为内部注意力(intra-attention),顾名思义就是对输入数据自身进行和传统注意力机制类似的处理。特别地,有q=k=v。
如果输入小批量样本X={x1,...,xn}∈Rn×d,xi∈Rd,那么一个自注意力机制任务中,任意一个键值对可以表示成(xi,xi),由其自身构成。从而当查询q=xi 时,有:
yi=f(xi,(x1,x1),(x2,x2),...,(xn,xn))∈Rd
其中,f 是注意力机制的一般范式。值得注意的是,通过注意力机制映射完之后的yi 的尺寸与输入一致。
实际中的自注意力
通常情况下,我们并不是直接取q=k=v,而是对原始输入xi 进行3种仿射变换,依次得到:qi=Wqxi,ki=Wkxi,vi=Wvxi,i=1,..,n .
然后再进行:
yi=f(qi,(k1,v1),(k2,v2),...,(kn,vn))∈Rd
即是用qi 作为查询,对所有的键值对进行注意力评分,然后加权得到第i 个输入的输出结果。如下图所示:
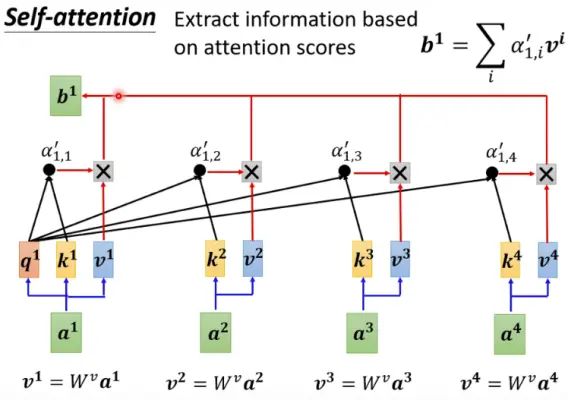
用同样的方法,我们可以并行地计算出和x1,...,xn 同样多的输出y1,...,yn。而且这些输出中的每一个都考虑到了所有的输入。
Self-attention vs. CNN
论文 《On the Relationship between Self-Attention andConvolutional Layers》 (https://arxiv.org/abs/1911.03584)指出,CNN其实就是自注意力机制的一种特例。
奠基之作
注意力机制的集大成者是如今赫赫有名的 Transformer 模型,本文中略过了不少注意力机制在该模型中的使用,这在本站下面这篇文章中将再次展开。感谢你看到这里!
番外:Att的Bug?
待更:https://zhuanlan.zhihu.com/p/645922048
https://www.evanmiller.org/attention-is-off-by-one.html
参考
- 动手学习深度学习|D2L Discussion - Dive into Deep Learning
- 详解深度学习中的注意力机制(Attention) - 知乎
- 拆 Transformer 系列二:Multi- Head Attention 机制详解
- 11.【李宏毅机器学习2021】自注意力机制 (Self-attention) -bilibili