【All U Need】Transformer 及其大模型之路
Seq2Seq
序列到序列学习,即 seq2seq(sequence to sequence)是 一个遵循 Encoder–Decoder 架构设计原则的模型。
顾名思义,该模型的输入是一个序列,输出也是一个序列。与传统 RNNs (输出和输出的长度是一致的)不同的是,编码器 Encoder 可以将一个可变长度的信号序列变为固定长度的向量表示,而解码器 Decoder 则将这个固定长度的向量自动解码并输出成变长的目标的信号序列。
具体到任务上, Seq2seq 通常在 NLP 中被广泛使用,利用 RNNs 作为编码器和解码器,于机器翻译等任务中。
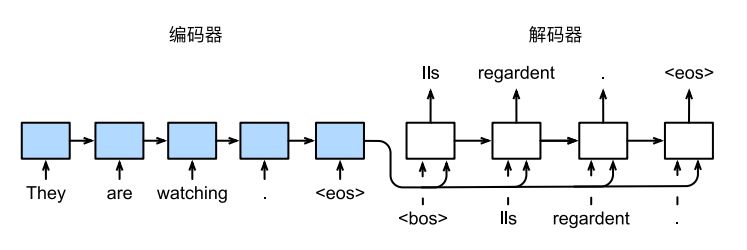
如上图所示,上图给出了一个利用 RNNs 进行机器翻译的示例。该模型的目标是将英文句子 They are watching. 翻译成了法语 Ils regardent. 其中,<eos> 是序列结束词元(end of sentence),<bos>是序列开始词元(begin of sentence)。
而具体实现上,是将英文句子 They are watching. 通过 encoder 编码成某种 representation,这个变量又作为 decoder 的初始隐状态,蕴含了原始句子的语义信息。于是 decoder 再同时接收法语的正确翻译句子作为监督信号,以生成和法语句子长度一致的输出结果。在推理时,需要移除监督,用上一时间步的输出作为下一时间步的输入。
Bahdanau Attention
传统的 RNN-besed Seq2seq 中通常只将 RNN encoder 最后一个时间步的隐状态输出作为 RNN decoder 的初始状态。而得益于注意力机制 “能够有选择性地关注到更重要的信息” 这种优良特性,如果将其应用在 RNN decoder 的隐状态上,可以有效地指导模型在每一个时间步更关注源语言句子的哪一个词,然后
再输出相应的目标语言的词。
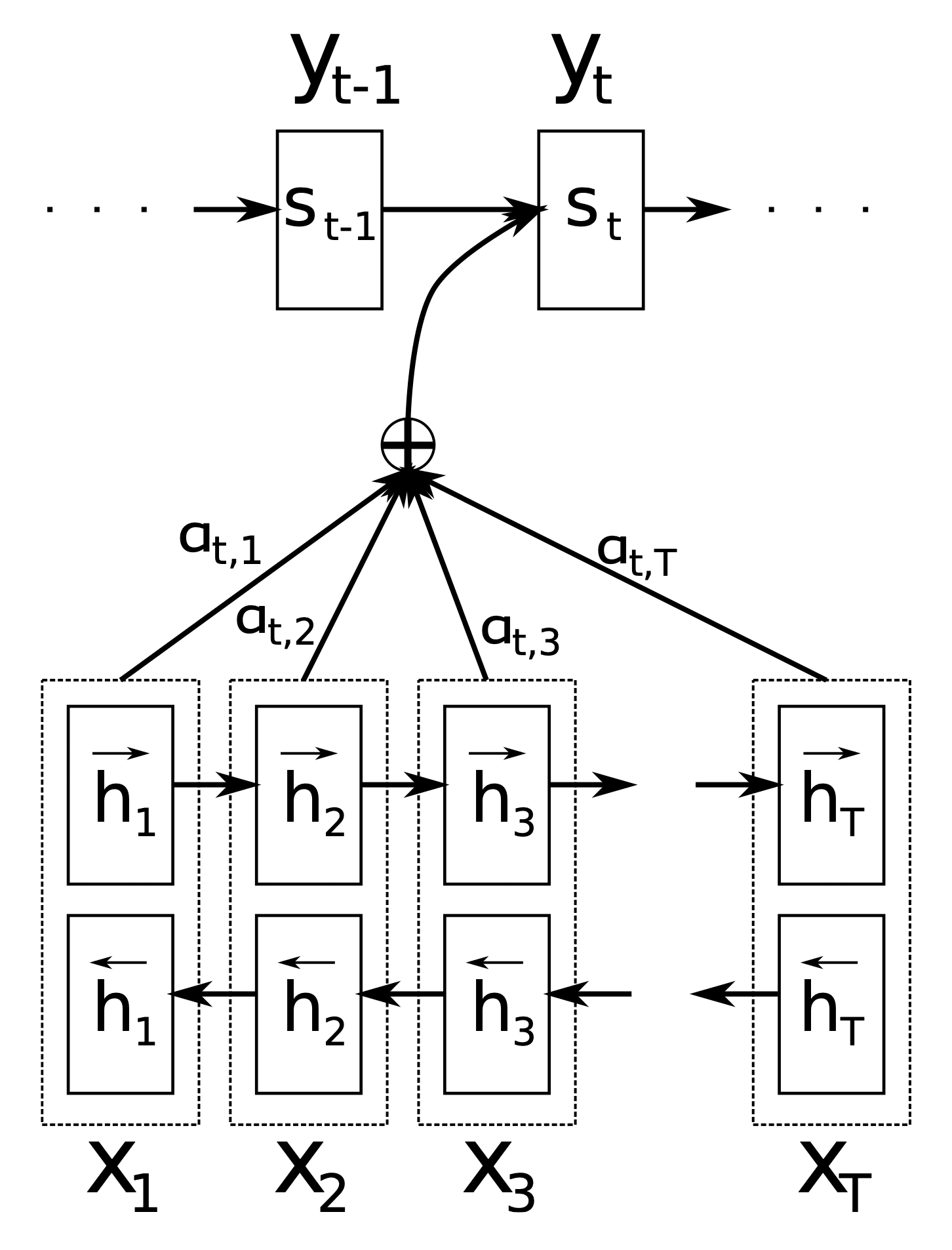
如上图所示,在时间步 时,模型会重新对 RNN encoder 每一个输入序列的隐状态进行注意力评分,然后再将新得到的这个 representation 作为 RNN decoder 的隐状态。
Transfromer
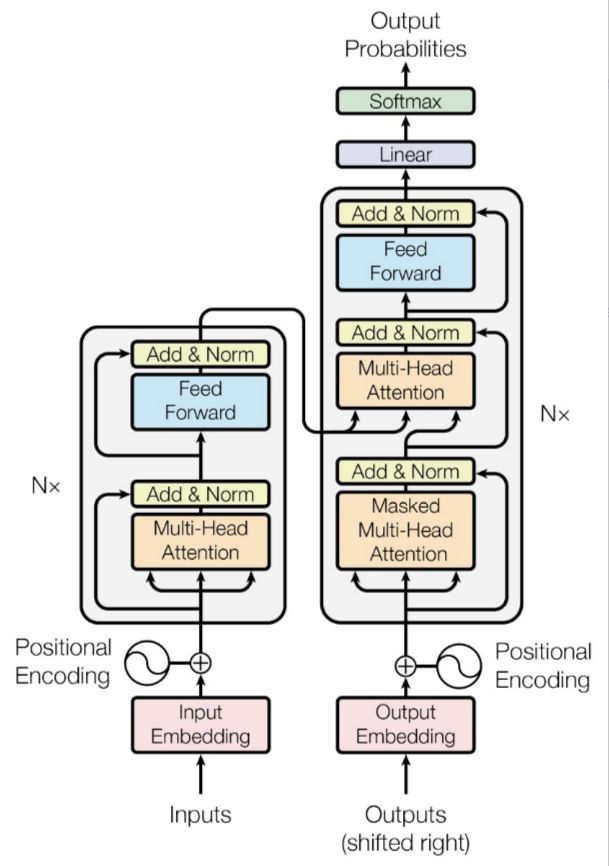
在关于注意力机制的文章中我们已经了解到了采用自注意力可以实现对每一个输出向量 都能综合所有输入序列得出一个输出. 并且这个计算是并行计算。
我们可以有这样的直觉,Self-attention 完成了和 RNN 一样的所谓“潜在向量”的生成任务。因此,我们完全可以将自注意力模块代替 传统 Seq2seq 中的循环神经网络,并且后者只能顺序计算,效率不高。除此之外,因为 Self-attention 是每个词和所有词计算 Attention,所以不管他们中间有多长距离,最大路径长度都只是 1,可以捕获长距离依赖关系。
于是乎,一个从头到尾只需要 Attention 的 Seq2seq 模型就此诞生了,再次扣题《Attention is all you need》。
位置编码
在深入考虑将 Self-attention 替代 RNN 的可行性时,我们很容易发现,Self-attention 不像 RNN 一样天然能够保持输入序列的先后顺序,而是直接把序列的顺序关系给忽略掉了。因此,我们需要人为地为其引入位置信息的概念。
Transformer给出的方案是使用位置编码(Position Encoding,PE)。
待更
(pytorch进阶之路)四种Position Embedding的原理及实现-CSDN博客
Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces (kexue.fm)
Transformer升级之路:1、Sinusoidal位置编码追根溯源 - 科学空间|Scientific Spaces (kexue.fm)
让研究人员绞尽脑汁的Transformer位置编码 - 科学空间|Scientific Spaces (kexue.fm)
引申:相加和拼接问题?
Add & Norm
Decoder Mask
- 防止泄露后面的词
- 结合encoder信息
PyTorch API
1 | torch.nn.MultiheadAttention |
Transformer模型详解(图解最完整版) - 知乎 (zhihu.com)
Key Size
突破瓶颈,打造更强大的Transformer - 科学空间|Scientific Spaces (kexue.fm)
BERT
从语言模型到Seq2Seq:Transformer如戏,全靠Mask - 科学空间|Scientific Spaces (kexue.fm)